مقدمه
نظرکاوی (تحلیل احساسات) یکی از زمینههای کاربردی پردازش زبان طبیعی است. هدف کلی نظر کاوی مشخص نمودن میزان رضایتمندی (نوع و شدت حس) شخص نویسنده نظر هست. بدیهی است که برای ماشین تشخیص عبارات حسی و تعیین میزان حس آنها (کمیسازی میزان حس) بدون کمک انسان، غیر ممکن است. لذا در روشهای تحلیل حس، ابتدا لیستی از عبارات حسی اولیه که معمولاً دارای مقدار عددی تعیین کننده میزان بار حسی میباشند، توسط اشخاص آشنا با زمینه نظرات تهیه شده و به عنوان ورودی به تحلیلگر حس متن داده میشود. سپس بوسیله الگوریتمهای مختلفی لیست اولیه عبارات حاوی حس بسط و تکمیل میگردد و میزان و شدت حس نیز با توجه به برخی از کلمات جمله از قبیل منفیکنندهها (معکوسکنندههای حسی) تنظیم میشود. تولید واژهنامه لغات حسی یکی از بخشهای اساسی و مهم برای تشخیص حس و شدت آن میباشد.
رویکردهای تولید واژهنامههای حسی
در چند سال گذشته، ساخت مجموعه لغات حاوی حس با بار حسی مثبت و منفی، یکی از روشهای مورد توجه محققان برای تشخیص حس جملات بوده است. بطور کلی روشهای تحلیل احساسات را میتوان به دو گروه تقسیمبندی نمود:
- روشهای مبتنی بر واژهنامه حسی و استفاده از دانش زمینه (یادگیری بدون ناظر یا شبهناظر)
- روشهای یادگیری باناظر
دقت روشهای مبتنی واژهنامه حسی کاملاً وابسته به مجموعه لغات حاوی حس و وزنهای از پیش تعیین شده است. این روشها بطور بدون ناظر و برای حوزههای عمومی قابل استفاده هستند. در رویکرد دوم (دستهبندی حسی متون) نیز از واژگان حسی به عنوان یکی از ویژگیهای مهم متن نظرات استفاده میشود.
از دیگر روشهای تشخیص حس عبارات استفاده از روشهای محاسبه شباهت معنایی کلمات میباشد. در این روشها برای تشخیص حس نظرات معمولاً از شباهت معنایی عبارات و لیست کوچکی از کلمات حاوی حس اولیه استفاده میشود. برای محاسبه شباهت معنایی معمولاً از سه روش استفاده میشود:
- مبتنی بر شبکه واژگان یا سایر لغتنامهها و دانشنامهها
- روابط وابستگی نحوی بین عبارت حاوی حس با کلمات موجود در واژهنامه حسی
- همرخدادی عبارات حاوی حس با کلمات موجود در لیست اولیه کلمات حاوی حس (روشهای یادگیر بدون ناظر) در درون پیکرههای مختلف مستندات
میتوان رویکرد سوم را زیر مجموعهای از رویکرد تشخصی حس مبتنی بر مجموعه لغات به شمار آورد با این تفاوت که لیست کلمات حاوی حس برای مستندات ورودی (داده شده) تشکیل میشود و از اینرو کارکرد بهتری برای تشخیص حس عبارات در حوزههای مختلف خواهد داشت.
با توجه به وابستگی زیاد روشهای مختلف تحلیل احساسات به لغتنامه واژگان حسی، در این بخش به توضیح روشهای مختلف واژهنامه حسی میپردازیم. بطور کلی از سه رویکرد ذیل برای تولید واژهنامههای حسی استفاده میشوند:
- مبتنی بر پیکره
- مبتنی بر لغتنامه و پایگاه دانش
- مبتنی بر روشهای یادگیر باناظر
برای دریافت اطلاعات بیشتر درباره این سه رویکرد به این مقاله مراجعه بفرمایید.
شبکه واژگان (WordNet)
شبکه واژگان دانشگاه پرینستون (Princeton WordNet یا PWN) یک پایگاه داده لغوی (Lexical Database) برای زبان انگلیسی است. شبکه واژگان حاوی لغات زبان طبیعی در قالب مجموعههای کلمات هممعنی (synonymous sets) یا بصورت مختصر گروه هممعنی (synset) میباشد که در دستههایی با توجه به نقش نحوی مانند فعل و اسم و صفت و قید تقسیمبندی شدهاند. این مجموعههای هممعنی توسط روابط معنایی مانند :هممعنایی (synonymy)، تضاد معنایی (antonymy)، رابطه شمول معنایی یا دربرداشتن (meronymy)، روابط سلسله مراتبی (Taxonomic) شامل دو نوع جزء به کل (hyponymy) و کل به جزء (hypernymy) و غیره با هم ارتباط دارند. اغلب شبکه واژگان برای ابهامزدایی و تعیین شباهت معنایی در کاربردهای مختلف پردازش زبان طبیعی و بازیابی اطلاعات مانند ترجمه ماشینی، استخراج اطلاعات و خلاصهسازی و … مورد استفاده قرار میگیرد. آخرین نسخه PWN (WordNet 3.1 database statistics) شامل حدود 155327 کلمه هست که در قالب 117597 گروه هممعنی سازماندهی شدند. اخیراً در بعضی از مقالات از شبکه واژگان برای استخراج واژگان حسی و ویژگیهای موجودیت مورد نظر استفاده شده است.
اکنون برای بیش از 40 زبان طبیعی در جهان شبکه واژگان ایجاد شده است که بین اغلب آنها با PWN لینک وجود دارد. برای ایجاد شبکه واژگان برای سایر زبانها معمولاً از دو رویکرد استفاده میشود:
- روش اول ساخت شبکه واژگان با استفاده از ترجمه گروههای هممعنی PWN مانند فردوسنت و شبکه واژگان فارسی دانشگاه تهران.
- در روش دوم ابتدا شبکه واژگان با استفاده از منابع زبان مقصد و روشهای زبانشناسی ایجاد شده و سپس بین گروههای هممعنی آن با PWN ازتباط (لینک) برقرار میشود. مانند فارسنت.
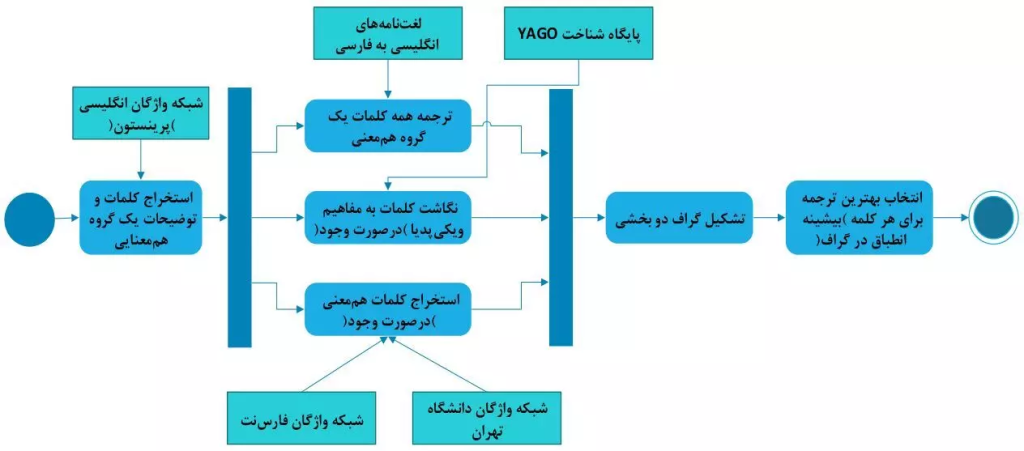
مراحل ایجاد گروههای هممعنی در شبکه واژگان فردوسنت
برای دریافت اطلاعات بیشتر درباره فردوسنت و سایر شبکههای واژگان زبان فارسی به این مقاله مراجعه بفرمایید.
شبکه واژگان حسی انگلیسی (SentiWordNet)
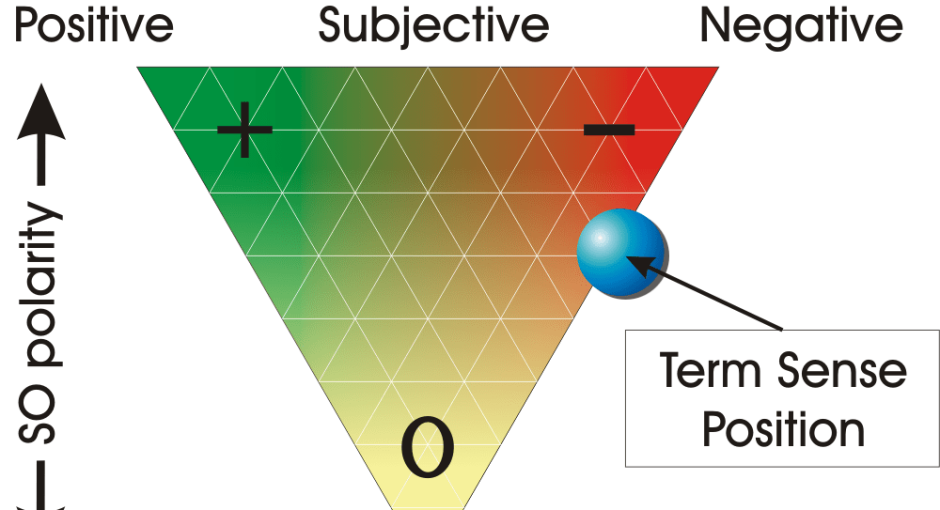
شبکه واژگان حسی انگلیسی (SentiWordNet) یکی از بهترین منابع موجود برای شناسایی کلمات حسی است که بر اساس تعیین میزان بار حسی هر گروه هممعنی در شبکه واژگان انگلیسی پرینستون (PWN) ایجاد شده است. شبکه واژگان حسی انگلیسی برای هر گروههای هممعنی میزان بار حسی منفی (negativity)، مثبت (positivity) و همچنین مقدار غیرحسی (objectivity) بودن (با توجه به مقدار حس مثبت و منفی) را با عددی بین صفر و یک مشخص میکند.
شبکه واژگان حسی انگلیسی نسخه 1.0 بوسیله یک الگوریتم یادگیر شبهناظر در 4 مرحله تشکیل شده است. سپس در نسخه سوم این شبکه واژگان حسی با استفاده از الگوریتم تکراری گام تصادفی بر روی گراف شبکه واژگان PWN، نتایج حاصل از نسخه قبل (SentiWordNet v1.0) را اصلاح کردند. تا کنون شبکه واژگان حسی انگلیسی به عنوان یک منبع واژگان حسی مستقل از دامنه و موضوع در بسیاری از کاربردهای نظر کاوی مورد استفاده قرار گرفته است. علاوه بر این با توجه به رابطه این واژهنامه با PWN ، از این منبع در بسیاری از کاربردهای نظرکاوی در زبانهای دیگر نیز (با برقرار کردن لینک بین شبکههای واژگان آن زبانها با PWN) استفاده شده است.
ساخت واژهنامه حسی زبان فارسی (حسنگار)
برای تولید حسنگار ابتدا با استفاده از نگاشت مفاهیم (گروههای هممعنی) در شبکه واژگان پرینستون به زبان فارسی، شبکه واژگان جامع (فردوسنت) ساخته شده است. در نهایت، با استفاده از فردوسنت، میزان بار حسی محاسبه شده برای هر گروه هممعنی در شبکه واژگان حسی انگلیسی به گروههای هممعنی متناظر با آن در حسنگار نگاشت میشود. پس در واقع با ابهامزدایی مفاهیم شبکه واژگان حسی انگلیسی، یک شبکه واژگان حسی برای زبان فارسی ایجاد شده است.
از شبکه واژگان حسی فارسی میتوان به عنوان یک واژهنامه حسی مرجع برای زبان فارسی استفاده نمود. علاوه بر این با توجه به وجود درجه اطمینان (برای کلمات موجود در هر گروه هممعنی در فردوسنت)، برای هر کلمه حسی علاوه بر بار حسی مثبت و منفی، میزان اطمینان (اعتبار) نیز خواهیم داشت.
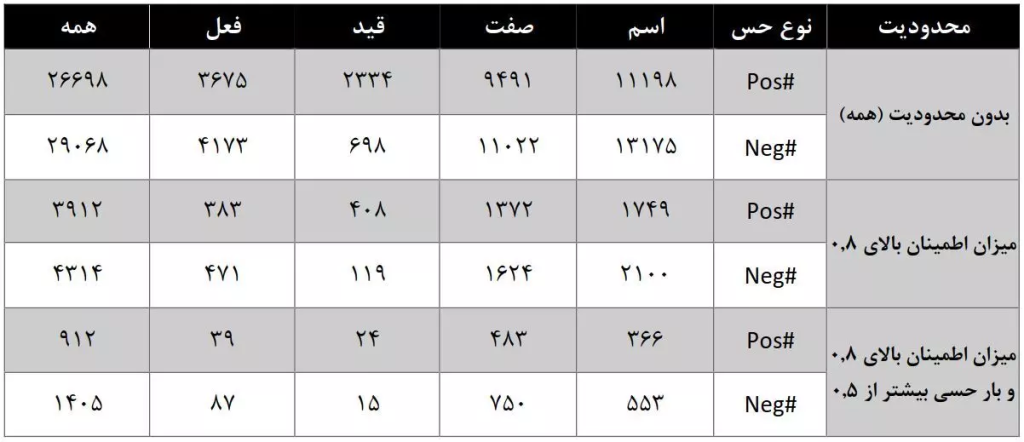
تعداد کلمات حسی مثبت (Pos#) و منفی (Neg#) موجود در شبکه واژگان حسی فارسی (حسنگار) براساس محدودیتهای مختلف
برای دریافت نسخه فعلی حسنگار به این منبع مراجعه فرمایید.
برای ارجاع درصورت استفاده از مطالب این نوشته، همچنین جهت اطلاع از منابع اصلی استفاده شده، یا دریافت توضیحات و جزئیات بیشتر به این مقاله مراجعه بفرمایید.