دعوت به همکاری
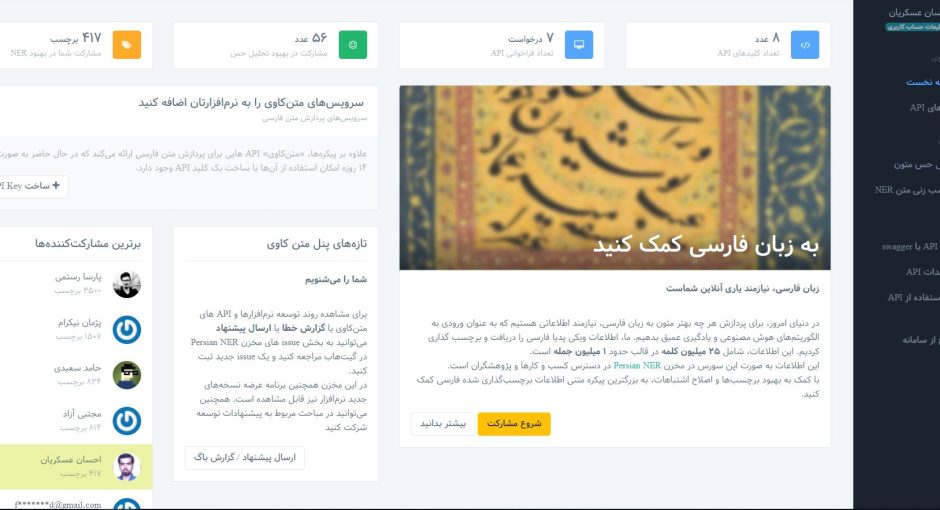
هدف ما این است که با مشارکت شما دوستان، بتوانیم پیکره برچسبخورده بزرگ و منبع باز (رایگان) ایجاد شده برای تشخیص موجودیتهای نامدار (Named Entity Recognition یا NER) در زبان فارسی را اصلاح کنیم. تا بدین ترتیب، با حل یکی از چالشهای زبان فارسی، قدم کوچکی برای احیای این زبان برداشته باشیم. برای این منظور پیکرهای در حدود ۲۵ میلیون توکن (واژه یا علامت) در قالب (نزدیک به) یک میلیون جمله از متون ویکیپدیا استخراج و با روشهای مختلف بصورت خودکار برچسبگذاری اولیه شده است. از شما دوستان خواهشمندیم که با تصحیح برچسبهای اشتباه یا برچسبزنی کلمات جاافتاده ما را در این راه یاری فرمایید. برای بالا بردن دقت کار هر جمله توسط دو نفر از دوستان مشارکتکننده، اصلاح و درصورت توافقنظر به پیکره اصلی اضافه میشود.
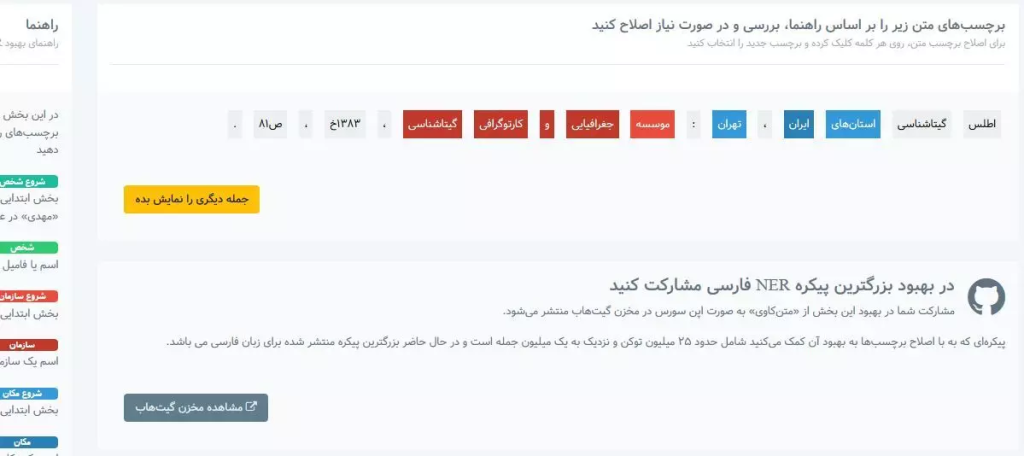
برای انجام این کار، سامانهای به آدرس ذیل ایجاد شده که میتوانید با ثبتنام و ورود به این سامانه در اوقات فراغت خود، بوسیله گوشی هوشمند یا سیستم (کامپیوتر) خود، براحتی با مصرف حجم کمی از اینترنت کار اصلاح برچسبگذاری را انجام بفرمایید.
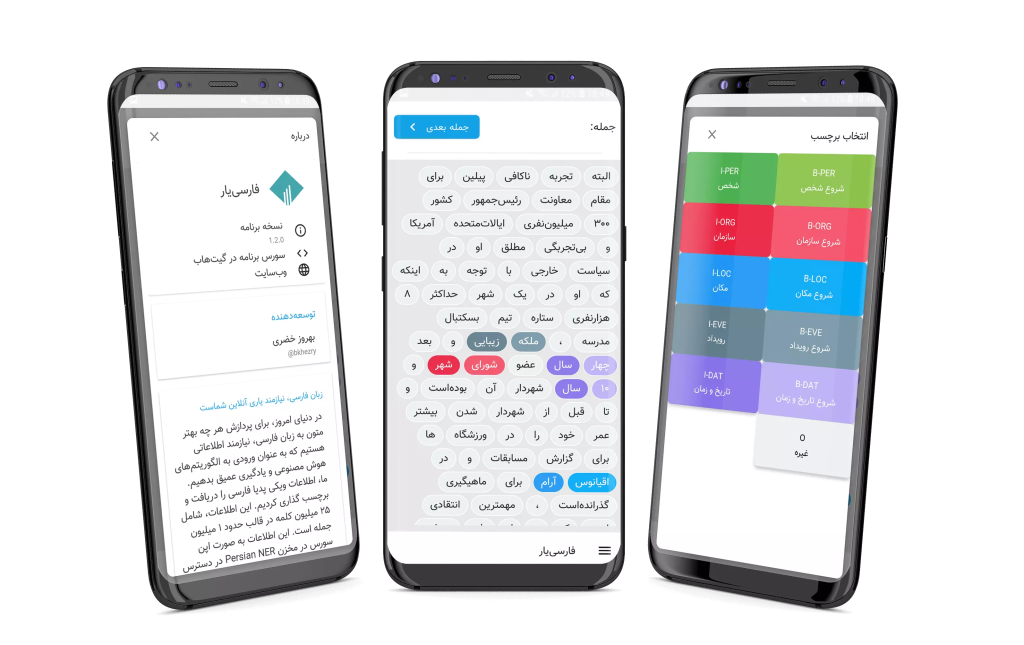
همچنین اپلیکیشن اندروید فارسییار بصورت متنباز برای برچسبزنی در کافه بازار قرار داده شده است.
خروجی پیکره برچسبگذاری شده در فواصل زمانی منظم در این آدرس برای پژوهشگران و علاقهمندان به تحقیقات پردازش زبان طبیعی قابل دسترس خواهد بود.
درنهایت سرویس (ابزار) NER زبان فارسی با کمک و استفاده از اولین خروجی پیکره برچسب خورده توسط دوستانی که در این پروژه مشارکت داشتند، در بخش API ابزارهای پردازش متن در سامانه متن کاوی فارسییار قرار داده شده است که برای عموم قابل استفاده است.
توضیح درباره ابزار تشخیص موجودیتهای نامی
یکی از ابزارهای مهم جهت استخراج اطلاعات از متن، شناسایی موجودیتهای نامدار[۱] یا کلمات خاص است. تشخیص موجودیتهای نامدار (نامی) به این معناست که اسامی خاص در یک متن را بتوان تشخیص داد و آنها را به ردههای مشخصی دستهبندی کرد. این ردهها چیزهای مختلفی میتوانند باشند که هدف ما استخراج ردههای ذیل است:
1. نام شخص (نام کوچک یا فامیل افراد و القاب و عناوین منتسب و یا همراه آنها)
2. نام سازمان (شرکت، نهادها، ادارات و تشکلهای خصوصی یا دولتی، نام بخشهای ادارات، گروه، تیم یا باشگاه ورزشی، وزارت، نام کارخانه یا نام فروشگاه معروف یا اصناف، نام نشریات و خبرگزاریها و …)
3. نام مکان (کشور، استان، شهر، روستا، کوه، رودخانه، دریا، صحرا، بنای تاریخی، خیابان، مجتمع مسکونی، منطقه یا ناحیه خاص، اشاره به مکان مدرسه یا کارخانه یا مغازه یا ایستگاه مترو یا حرم یا … در متن). لطفاً توجه شود که محل اشیا و … مثل “زیر میز”، “در قلبم” جزء اسامی مکان نیست.
4. نام یا عبارت رویداد (حادثه، تصادف، قتل، جنگ، سرقت، آتشسوزی، عملیات تروریستی یا نظامی، برگزاری مسابقات مختلف، انتخابات، مذاکرات یا اجلاس، جشن یا کنگره یا …، توافقنامه، تظاهرات، مناسبتهای مختلف و …)
5. عبارت زمان یا تاریخ (روز هفته، ماه، سال، ساعت، تاریخ، قرن، دوره یا عصر زمانی، اشاره به تاریخ یا زمان خاص یا نسبی مثل “دیروز”، “یک ساعت قبل”، “نیمه شب” و …)
رویکردهای شناسایی موجودیتهای نامی
متاسفانه تهیه لیست اسامی خاص خیلی وقتها کمکی چندانی نمیکند، چون نوعاً کلماتی وجود دارند که میتوانند با توجه به جمله و متن، در چند رده قرار بگیرند. برای مثال :
- “۱۱ سپتامبر”، میتواند اشاره به حادثه ۱۱ سپتامبر داشته و از رده رویداد یا از رده تاریخ/زمان باشد.
- “صیاد شیرازی” میتواند در جمله به یک خیابان (رده مکان) یا نام یک شخص (رده اشخاص) باشد.
دو رویکرد استفاده از الگوهای متنی (مثلا آقای ؟ اشاره به نام شخص دارد) و استفاده از روشهای یادگیری ماشین برای حل این مشکل وجود دارد. با توجه به ضعفها و موارد استثنای زیاد، استفاده از رویکرد الگوهای متنی به تنهایی خیلی کاربردی نیست و رویکرد مبتنی بر روشهای یادگیری ماشین توصیه میشود. در روشهای یادگیری ماشین از قواعد از پیشتعیین شده و لیست لغات استفاده نمیشود و به جای آن از حجم زیادی از دادههای برچسبخورده (یا در برخی موارد بدون برچسب) استفاده میشود. منظور از پیکره برچسب خورده، متون زیادی است که موجودیتهای آن بوسیلهی یک روش دستی یا نیمه دستی (توسط انسان) مشخص (برچسبگذاری) شده باشد. از پیکره برچسب خورده برای فرایند یادگیری روشهای هوشمند استفاده میشود. اما متاسفانه چالش اصلی این رویکرد، عدم وجود پیکره برچسب خورده مناسب و کافی برای زبان فارسی است.