در مقالات قبل به مقایسه ویژگیهای کتابخانهها و ابزارهای پردازش زبان طبیعی اشاره شد. سپس 9 کتابخانه محبوب پردازش متن معرفی و نمونه کد آنها قرار داده شد. بخشهای دیگر این مقاله:
- بخش اول – معرفی بهترین کتابخانههای پردازش متن (NLTK, SpaCy, CoreNLP)
- بخش دوم – معرفی بهترین کتابخانههای پردازش متن (TextBlob, Pattern, StanfordNLP)
- بخش سوم – معرفی بهترین کتابخانههای پردازش متن (Polyglot, Gensim, Illinois NLP Curator)
- بخش چهارم – معرفی بهترین کتابخانههای پردازش متن (Spark-NLP, OpenNLP, SyntaxNet)
- بخش پنجم – معرفی بهترین کتابخانههای پردازش متن (GATE, RapidMiner, MALLET, FreeLing)
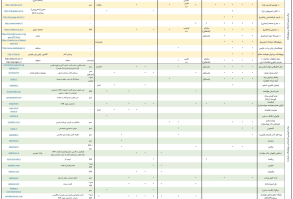
در جدول زیر بطور خلاصه لیست کتابخانهها و جعبه ابزارهای معروف و رایگان پردازش متن، ویژگیهای مهم آنها و ابزارهای پیادهسازی شده در هریک را گردآوری کردیم.
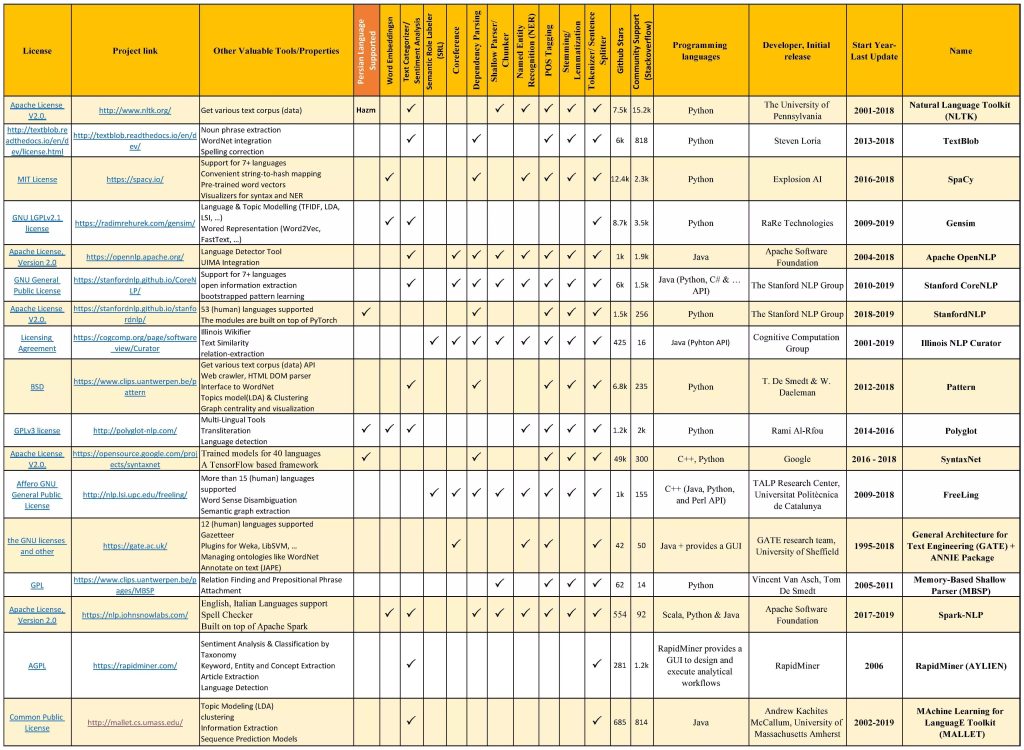
مقایسه ویژگیها و امکانات کتابخانههای (جعبه ابزار) محبوب و رایگان پردازش زبان طبیعی تا سال 2019
ذکر چند نکته درباره این جدول را لازم میدانیم. ستون دوم سال تولید و سالی که آخرین نسخه ابزار (بروزرسانی) در آن ارائه شده است را نشان میدهد. در ستون ششم، تعداد ستارهی داده شده به پروژه مربوط به هر کتابخانه در گیتهاب (یا پرستارهترین پروژه مرتبط با آنها) را به عنوان سنجه میزان محبوبیت درنظر گرفتیم. همچنین از شاخص تعداد سوالات پرسیده شده در StackoverFlow (درباره هر کتابخانه)، به عنوان مبنای میزان استفاده و جامعه بهرهبردار آن کتابخانه استفاده شده است. ستون هفدهم به پشتیبانی از زبان فارسی هر کتابخانه (همه یا بعضی از ابزارهای آن) اختصاص داده شده است. این اطلاعات و ارقام در تاریخ 15 اسفند 97 جمعآوری شدند.
در این بخش به معرفی چند جعبه ابزار پردازش متن محبوب و کاربردی دیگر میپردازیم.
کتابخانه SparkNLP
کتابخانه SparkNLP، بوسیله شرکت John Snow Labs برای استفاده از ماژولهای کاربردی پردازش متن روی بستر Apache Spark و کتابخانه Spark ML توسعه یافته است. این کتابخانه برای استفاده در زبانهای اسکالا، پایتون و جاوا و با هدف محاسبات مقیاسپذیر (scalable) برای دادههای حجیم بصورت توزیع شده، ایجاد شده است. اغلب امکانات این کتابخانه بصورت رایگان در اختیار پژوهشگران قرار داده شده است و تنها امکانات بخش یادگیری عمیق و ارتباط با Tensorflow بصورت تجاری میسر است.
بوسیله کتابخانه SparkNLP قادر خواهید بود که اغلب ابزارهای برچسبزنی کتابخانههای spaCy و StanfordNLP برای زبان انگلیسی را، روی بستر Spark بشکل توزیع شده، استفاده کنید. متاسفانه مدلهای آموزش داده شده برای ابزارهای مختلف این کتابخانه تنها جهت بکارگیری در زبان انگلیسی و ایتالیایی است. قابلیتها و ماژولهای اصلی این کتابخانه در شکل زیر نشان داده شده است.
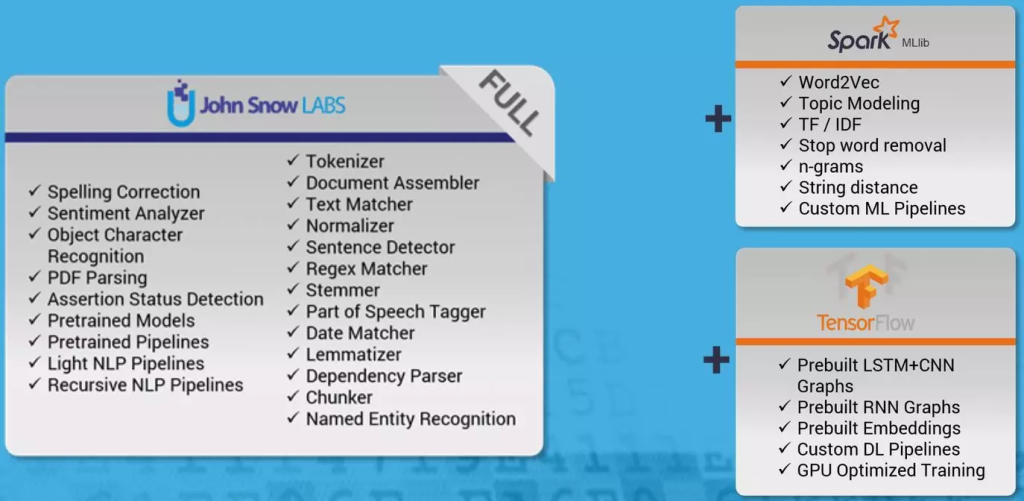
برای نصب و راهاندازی این کتابخانه به این آدرس مراجعه کنید. همچنین برای مشاهده مثال نسبتاً کامل از استفاده از ابزارهای مختلف SparkNLP و دستهبندی حسی متن به این آدرس مراجعه فرمایید.
شرکت جان اسنو برای نشان دادن دقت و سرعت اجرای ابزارهای تولید شده خود، این کتابخانه را با SpaCy (که یک کتابخانه فوقالعاده سریع و بهینه شده با C++ بوسیله Cython میباشد) مقایسه نموده است. در شکلهای ذیل، نتایج خلاصه آزمایشات صورت گرفته را مشاهده میکنید.
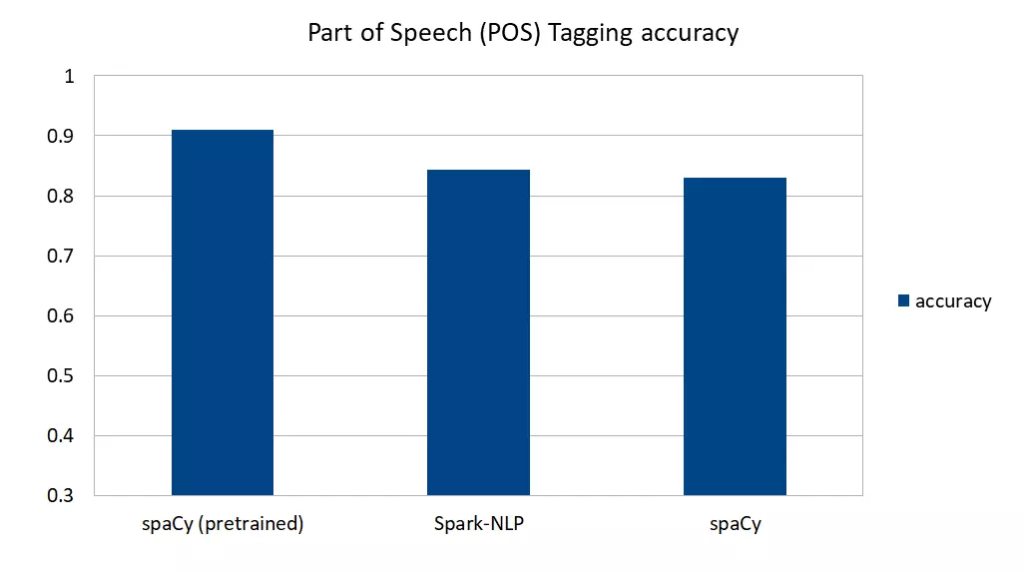
مقایسه دقت SpaCy و SparkNLP برای برچسبزنی نقش کلمات در جمله برای زبان انگلیسی (مقدار دقت بیشتر بهتر است)
در شکل فوق نشان داده شده است که علیرغم ضعف SparkNLP نسبت به SpaCy از نظر دقت، ولی از کیفیت قابل قبولی برخوردار است.
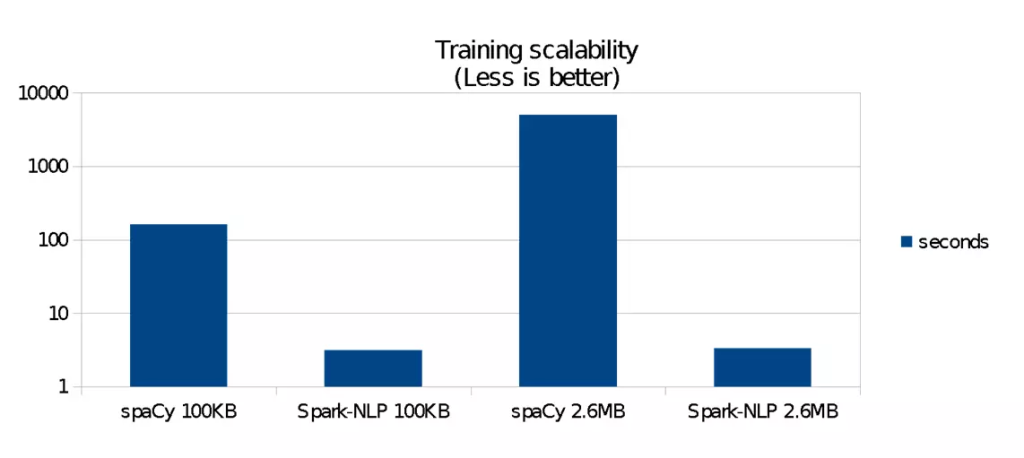
مقایسه کارایی (زمانی) SpaCy و SparkNLP در آموزش مدل یادگیر برای برچسبزنی نقش کلمات (مقدار زمان کمتر بهتر است)
همانطور که مشاهده میکنید با افزایش حجم دادهها، زمان آموزش کتابخانه SparkNLP میزان ناچیزی افزایش پیدا کرده است.
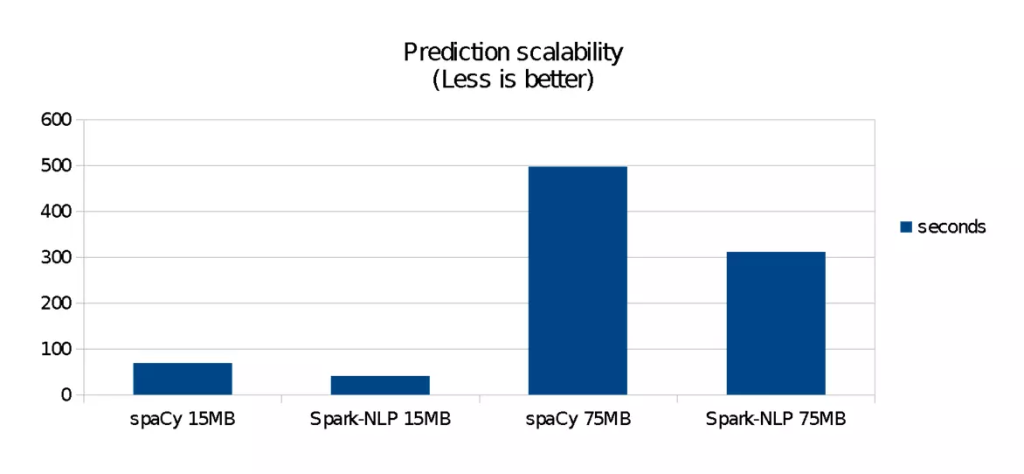
مقایسه سرعت اجرای (زمان مصرف شده برای پیشبینی برچسب نقش کلمات) SpaCy و SparkNLP (مقدار زمان کمتر بهتر است)
لطفاً برای مشاهده شبه کد و جزئیات این آزمایشات در فاز آموزش، اجرا و توضیحات بیشتر، به مقالات اصلی آنها در سایت oreilly مراجعه فرمایید.

کتابخانه Apache OpenNLP
کتابخانه OpenNL، یکی از پروژههای نبستاً باسابقه شرکت محبوب Apache برای پردازش زبان طبیعی است. طبق معمول پروژههای قدیمی شرکت آپاچی این کتابخانه نیز با زبان جاوا توسعه داده شده و بخوبی پشتیبانی و بروزرسانی میشود. البته نسخههای غیررسمی و پورت شده این کتابخانه برای زبانهای مختلف از جمله سیشارپ، پایتون و … موجود است. در این کتابخانه تعداد زیادی از ابزارهای پایه پردازش متن بوسیله روشهای مبتنی بر یادگیری ماشین پیادهسازی شده است. البته مدل آموزش داده شدهی اغلب این ابزارها فقط برای زبان انگلیسی (و بندرت برای چینی و عربی) آماده شده است.
در دو جدول زیر (گرفته شده از این مقاله در سال 2016) نتایج مقایسه کتابخانههای مختلف پردازش متن از جمله OpenNLP برای دو ابزار قطعهبند و شناسایی موجودیتهای نامی متن انگلیسی روی دو پیکره مختلف (متن رسمی و متن محاورهای درون شبکهی اجتماعی توئیتر) نمایش داده شده است.
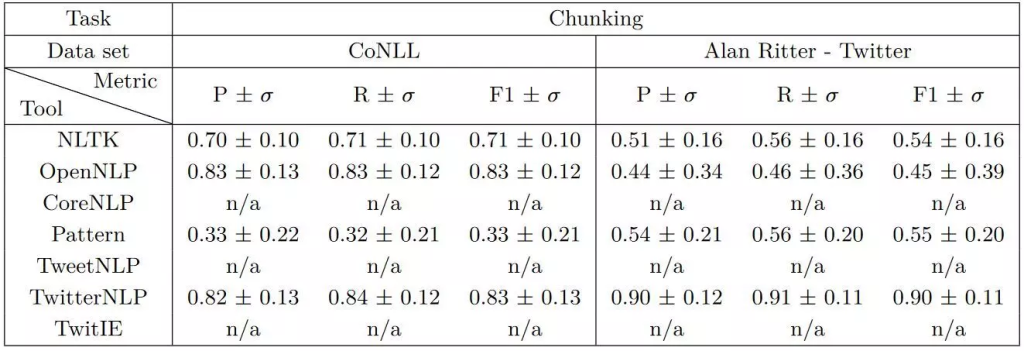
مقایسه کیفیت نتایج کتابخانههای مختلف برای ابزار قطعهبند متن انگلیسی بر روی دو پیکره مختلف (ستون اول نتایج منظور از P دقت، ستون دوم R منظور بازآوری و ستون سوم معیار F1 که از ترکیب دقت و بازآوری بدست میآید)
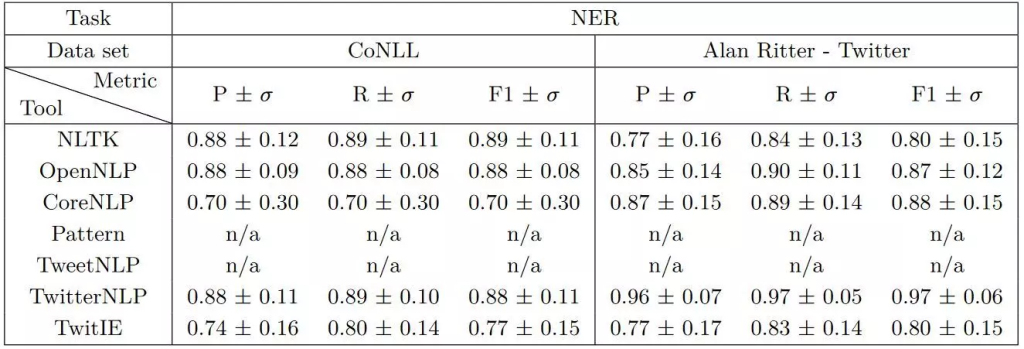
مقایسه کیفیت نتایج کتابخانههای مختلف برای ابزار تشخیص موجودیتهای نامدار (انواع اسامی خاص) متن انگلیسی بر روی دو پیکره مختلف (ستون اول نتایج منظور از P دقت، ستون دوم R منظور بازآوری و ستون سوم معیار F1 که از ترکیب دقت و بازآوری بدست میآید)
برای استفاده از کتابخانه جاوا OpenNLP باید JDK 8 و Maven 3.3.9 (یا نسخههای بالاتر) را نصب کنید. برای مشاهده مستندات کامل این کتابخانه به این آدرس مراجعه فرمایید.

کتابخانه SyntaxNet
کتابخانه SyntaxNet، به عنوان یک ابزار (toolkit) جانبی کتابخانه TensorFlow برای پردازش زبان طبیعی توسط شرکت گوگل در سال 2016 توسعه یافته است. علت ستاره زیاد این کتابخانه در گیتهاب نیز قرار گرفتن پروژه مربوط به SyntaxNet درون (زیربخش) پروژه TensorFlow است. در واقع این کتابخانه یک چارچوب کدباز (open-source) برای فهم (درک) زبانهای طبیعی مختلف (Natural Language Understanding-NLU) مبتنی بر شبکههای عصبی است.
در شکل زیر دقت ابزارهای تقطیع کلمات و برچسبزنی نقش کلمات این کتابخانه با کتابخانههای SpaCy، Stanford و NLTK روی سه مجموعه داده متنی مقایسه شده است. البته در فضای دانشگاهی این کتابخانه به پارسر وابستگی آن (پارسر Parsey McParseface که مدلهای از پیش آموزش داده شدهی آن برای زبانهای مختلف موجود میباشد) معروف شده است.
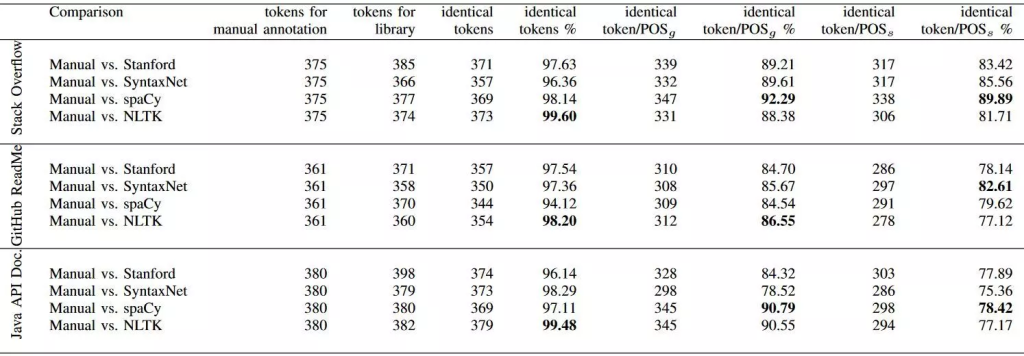
مقایسه دقت برخی از ابزارهای کتابخانههای SyntaxNet، Stanford، Spacy و NLTK روی سه پیکره متنی مختلف
برای نصب و استفاده از این کتابخانه باید از پایتون نسخه 2.7 و سیستم عامل Ubuntu یا OSX استفاده نمایید. شما میتوانید جهت کسب اطلاعات کافی برای نصب و راهاندازی این کتابخانه به این آدرس مراجعه فرمایید. البته پیشنهاد میشود برای استفاده از مدلهای از پیش آموزش داده شده (pre-Trained) در تحقیقات آکادمیک خود از وب سرویسهای آنلاین استفاده کنید:
نحوه نصب و نمونه کد پایتون algorithmia :
# Install the Algorithmia Python client with pip:
# pip install algorithmia
import Algorithmia
input = {
"src": "من با پدر احمد به مدرسه شهید قاسمی رفتیم.",
"format": "tree",
"language": "persian"
}
client = Algorithmia.client('YOUR_API_KEY')
algo = client.algo('deeplearning/Parsey/1.1.1')
algo.set_options(timeout=300) # optional
print(algo.pipe(input).result)خروجی کد فوق:
Input: من با پدر احمد به مدرسه شهید قاسمی رفتیم.
Parse:
رفتیم. VERB++V_PA ROOT
+-- من PRON++PRO nsubj
+-- پدر NOUN++N_SING nmod
| +-- با ADP++P case
| +-- احمد NOUN++N_SING name
+-- مدرسه NOUN++N_SING nmod
+-- به ADP++P case
+-- شهید NOUN++N_SING nmod:poss
+-- قاسمی NOUN++N_SING nameمنابع برتر
- COGCOMPNLP: Your Swiss Army Knife for NLP.; In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC-2018). 2018.
- Choosing an NLP library for analyzing software documentation: a systematic literature review and a series of experiments.; In Proceedings of the 14th International Conference on Mining Software Repositories, pp. 187-197. IEEE Press, 2017.
- Comparing the performance of different NLP toolkits in formal and social media text.; In 5th Symposium on Languages, Applications and Technologies (SLATE2016), 2016.
- https://www.johnsnowlabs.com/spark-nlp/
- https://www.oreilly.com/ideas/comparing-production-grade-nlp-libraries-accuracy-performance-and-scalability
- Announcing SyntaxNet: The World’s Most Accurate Parser Goes Open Source
استفاده از این مقاله با ذکر منبع “سامانه متن کاوی فارسییار – text-mining.ir“، بلامانع است.