
در مقالات قبل به مقایسه ویژگیهای کتابخانهها و ابزارهای پردازش زبان طبیعی اشاره شد. سپس شش کتابخانه محبوب پردازش متن معرفی و نمونه کد آنها قرار داده شد. بخشهای دیگر این مقاله:
- بخش اول – معرفی بهترین کتابخانههای پردازش متن (NLTK, SpaCy, CoreNLP)
- بخش دوم – معرفی بهترین کتابخانههای پردازش متن (TextBlob, Pattern, StanfordNLP)
- بخش سوم – معرفی بهترین کتابخانههای پردازش متن (Polyglot, Gensim, Illinois NLP Curator)
- بخش چهارم – معرفی بهترین کتابخانههای پردازش متن (Spark-NLP, OpenNLP, SyntaxNet)
- بخش پنجم – معرفی بهترین کتابخانههای پردازش متن (GATE, RapidMiner, MALLET, FreeLing)
در جدول زیر بطور خلاصه لیست کتابخانهها و جعبه ابزارهای معروف و رایگان پردازش متن، ویژگیهای مهم آنها و ابزارهای پیادهسازی شده در هریک را گردآوری کردیم.
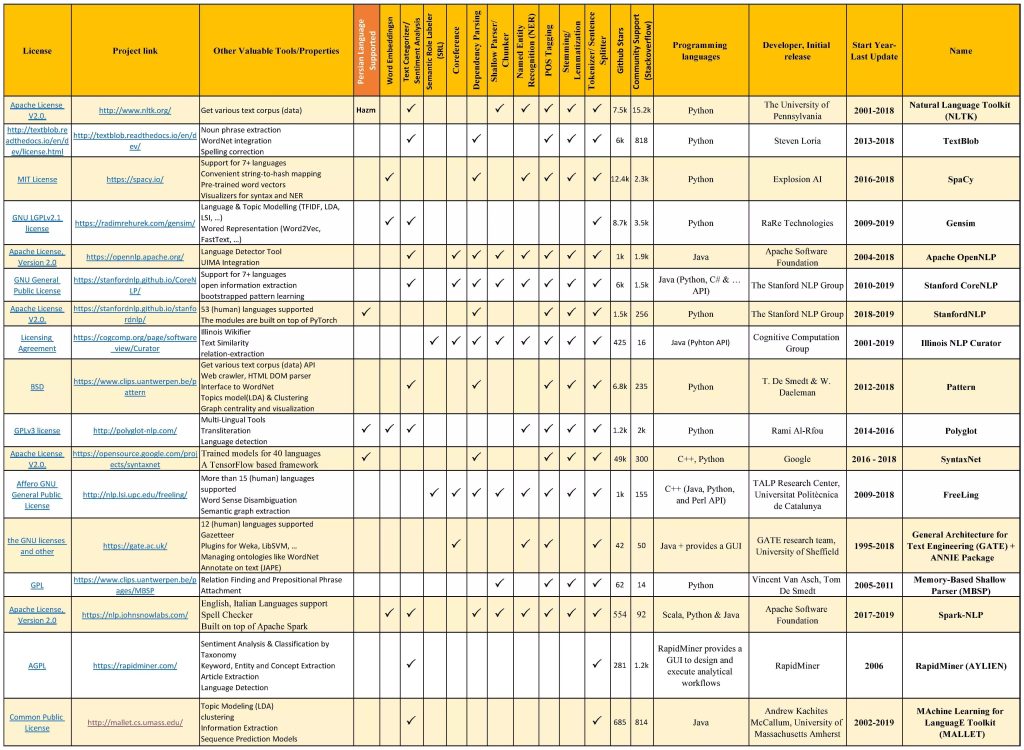
مقایسه ویژگیها و امکانات کتابخانههای (جعبه ابزار) محبوب و رایگان پردازش زبان طبیعی تا سال 2019
ذکر چند نکته درباره این جدول را لازم میدانیم. ستون دوم سال تولید و سالی که آخرین نسخه ابزار (بروزرسانی) در آن ارائه شده است را نشان میدهد. در ستون ششم، تعداد ستارهی داده شده به پروژه مربوط به هر کتابخانه در گیتهاب (یا پرستارهترین پروژه مرتبط با آنها) را به عنوان سنجه میزان محبوبیت درنظر گرفتیم. همچنین از شاخص تعداد سوالات پرسیده شده در StackoverFlow (درباره هر کتابخانه)، به عنوان مبنای میزان استفاده و جامعه بهرهبردار آن کتابخانه استفاده شده است. ستون هفدهم به پشتیبانی از زبان فارسی هر کتابخانه (همه یا بعضی از ابزارهای آن) اختصاص داده شده است. این اطلاعات و ارقام در تاریخ 15 اسفند 97 جمعآوری شدند.
در این بخش به معرفی چند جعبه ابزار پردازش متن محبوب و کاربردی دیگر میپردازیم.

کتابخانه Polyglot
کتابخانه Polyglot،یکی از کتابخانههای پرطرفدار پردازش متن در زبان پایتون هست. با وجود پشتیبانی ضعیف و عدم بروزرسانی این کتابخانه، بدلیل پشتیبانی از زبانهای طبیعی متعدد (بین 16 الی 169 زبان در ابزارهای مختلف) از جمله فارسی، از محبوبیت خوبی بین پژوهشگران برخوردار است.
نصب و راهاندازی:
pip install -U polyglot
pip install pyicu # or install using .whl file from "https://www.lfd.uci.edu/~gohlke/pythonlibs/#pyicu"
pip install pycld2
pip install morfessorسپس باید مدلهای مورد نیاز خود را دانلود کنید. برای اطلاع از مدلهای موجود از شبه کد زیر استفاده نمایید:
import polyglot
from polyglot.downloader import downloader
# supported language for special nlp task:
print(downloader.supported_languages_table(task="ner2"))
# supported tools (tasks) for special language:
print(downloader.supported_tasks(lang="fa"))برای دانلود مدلهای polyglot دو روش وجود دارد:
1- دانلود مستقیم (در کنسول):
polyglot download --help
polyglot download morph2.fa
polyglot download embeddings2.fa
polyglot download embeddings2.en
polyglot download ner2.fa
polyglot download sentiment2.fa
polyglot download transliteration2.fa2- دانلود درون سورس کد:
import polyglot
from polyglot.downloader import downloader
#downloader.download_dir = r"E:\polyglot"
downloader.download("morph2.fa")
downloader.download("embeddings2.fa")
downloader.download("embeddings2.en")
downloader.download("ner2.fa")
downloader.download("sentiment2.fa")
downloader.download("transliteration2.fa")چنانچه از سیستم عامل ویندوز استفاده میکنید، هنگام استفاده از این کتابخانه احتمالاً با خطاهایی مواجه میشوید. برای حل آنها دستورالعمل ذیل را انجام بدهید:
- خطای ImportError: cannot import name SIGPIPE : درون فایل “C:\Python36\Lib\site-packages\polyglot\__main__.py”، خط 9 (from signal import signal, SIG_DFL, SIGPIPE) و خط 28 (signal(SIGPIPE, SIG_DFL)) را حذف کنید.
- خطای IndexError: list index out of range : درون فایل “C:\Python36\Lib\site-packages\polyglot\downloader.py”، در تابع fromcsobj واقع در خط 205، مقدار path.sep را با “/” جایگزین نمایید (4 مورد در خطوط 208، 210، 215 و 216 باید در این تابع جایگزین شوند).
نمونه کد استفاده از ابزارهای مختلف این کتابخانه:
import polyglot
from polyglot.text import Text, Word
blob = u"سلام! به سامانه متن کاوی فارسی یار خوش آمدید. ارائه دهنده بهترین ابزارهای متن کاوی فارسی در ایران."
text = Text(blob) # , hint_language_code='fa'
print("Language Detected: Code={}, Name={}\n".format(text.language.code, text.language.name))
print(text.sentences)
print(text.tokens)
print(text.morphemes)
print(text.entities)
print(" ".join(map(str,text.transliterate("en"))))
print("{:<16}{}".format("Word", "Polarity")+"\n"+"-"*30)
for w in text.words[-10:]:
print("{:<16}{:>2}".format(w, w.polarity))خروجی این کد (به ترتیب خروجی ابزارهای تشخیص زبان، تقطیع جملات، تقطیع کلمات، تحلیل لغوی و بنواژهیابی، شناسایی موجودیتهای نامی، ترجمه و نهایتاً شناسایی لغاتی حسی):
Language Detected: Code=fa, Name=فارسی
[Sentence("سلام!"), Sentence("به سامانه متن کاوی فارسی یار خوش آمدید."), Sentence("ارائه دهنده بهترین ابزارهای متن کاوی فارسی در ایران.")]
['سلام', '!', 'به', 'سامانه', 'متن', 'کاوی', 'فارسی', 'یار', 'خوش', 'آمدید', '.', 'ارائه', 'دهنده', 'بهترین', 'ابزارهای', 'متن', 'کاوی', 'فارسی', 'در', 'ایران', '.']
['سلام', '!', ' به سامانه متن کاوی فارسی یار ', 'خوش', ' آمدید. ارائه دهنده بهترین ', 'ابزار', 'های', ' متن کاوی فارسی در ', 'ایران', '.']
[I-LOC(['ایران'])]
slam bh samanh mtn kavi farsi iar josh amdid araeh dhendh bhtrin abzarhai mtn kavi farsi dr airan
Word Polarity
------------------------------
ارائه 0
دهنده 0
بهترین 0
ابزارهای 0
متن 0
کاوی 0
فارسی 0
در 0
ایران 0
. 0همانطور که مشاهده میکنید، دقت خروجی polyglot برای زبان فارسی رضایتبخش نیست!

کتابخانه Gensim
کتابخانه gensim، یکی از محبوبترین و بهترین ابزارهای مدلسازی موضوع (topic modelling) و بازنمایی متن (تبدیل متن به بردار) است. در این کتابخانه اغلب روشهای مشهور تعبیه کلمات (word embedding) و بازنمایی کلمات (Word Representation) در زبان پایتون پیادهسازی شده و بخوبی بروزرسانی و پشتیبانی میشوند. شما برای پیشپردازش متن بهتر است از کتابخانههای دیگر مانند NLTK یا SpaCy استفاده نموده و در تحلیلهای بعدی (مانند استخراج کلمات کلیدی یا موضوعات درون متن) از این کتابخانه استفاده نمایید.
نصب و راهاندازی:
pip install -U gensimنمونه کد مدلسازی موضوعی متن:
import gensim
from pprint import pprint # pretty-printer
documents = [u"سلام! به سامانه متن کاوی فارسی یار خوش آمدید.",
" ارائه دهنده بهترین ابزارهای متن کاوی فارسی در ایران."]
stoplist = set(u'و را که به با برای از ها های ی می نمی این آن است هست نیست باشد شد کرد '.split())
texts = [[word for word in document.lower().split() if word not in stoplist] for document in documents]
dictionary = gensim.corpora.Dictionary(texts)
bow_corpus = [dictionary.doc2bow(doc) for doc in texts]
##Then the dictionary and corpus can be used to train using LDA
lda_model = gensim.models.ldamodel.LdaModel(bow_corpus, num_topics = 2, id2word = dictionary, passes = 10)
pprint(lda_model.print_topics(2, 5))
print('------------------------------------')
lsi_model = gensim.models.lsimodel.LsiModel(corpus=bow_corpus, id2word=dictionary, num_topics=2)
pprint(lsi_model.print_topics(2, 5))خروجی:
[(0, '0.105*"متن" + 0.104*"کاوی" + 0.104*"فارسی" + 0.063*"ارائه" + ''0.063*"ابزارهای"'),
(1, '0.073*"خوش" + 0.073*"آمدید." + 0.073*"یار" + 0.072*"سلام!" + ''0.072*"سامانه"')]
------------------------------------
[(0, '0.415*"متن" + 0.415*"کاوی" + 0.415*"فارسی" + 0.225*"بهترین" + ''0.225*"ارائه"'),
(1, '0.327*"آمدید." + 0.327*"سلام!" + 0.327*"یار" + 0.327*"سامانه" + ''0.327*"خوش"')]
کتابخانه Illinois NLP Curator
کتابخانه NLP Curator، شامل ابزارهای کاملی از پردازش زبان طبیعی است که در دانشگاه ایلینوی آمریکا بوسیله زبان جاوا توسعه داده شده است. البته API آن به زبان پایتون نیز تهیه شده است.
نصب و راهاندازی (API زبان پایتون):
دستورات لازم برای نصب:
pip install cython
pip install ccg_nlpyبرای از نصب و استفاده از این کتابخانه باید به چند نکته توجه داشته باشید:
- نصب Java Development Kit (JDK) و ایجاد متغیر سیستمی (environment variable) به نام JDK_HOME برای قرار دادن آدرس محل نصب جاوا مثل “”C:\Program Files\Java\jdk1.XXXX”
- استفاده از فیلترشکن (در ایران) هنگام نصب و استفاده از API پایتون (بشکل ریموت یا آنلاین)
- برای دانلود کتابخانهها و مدلها (حدود 650 مگابایت) و استفاده بصورت آفلاین (لوکال)، بعد از نصب maven و افزودن آدرس جاوا به Path در متغیرهای سیستمی، دستورات زیر را اجرا و عمل نمایید:
python -m ccg_nlpy download
pip install -U jnius
# add "C:\Program Files\Java\jdk1.XXXX\jre\bin\client" or "C:\Program Files\Java\jdk1.XXXX\jre\bin\server" to your Path of Windows environment نمونه کد استفاده از API پایتون:
############ for remote (online) running #############
#from ccg_nlpy import remote_pipeline
#pipeline = remote_pipeline.RemotePipeline()
############ for local (offline) running #############
from ccg_nlpy import local_pipeline
pipeline = local_pipeline.LocalPipeline()
doc = pipeline.doc("Hello, how are you. I am doing fine")
print(doc.get_lemma)
print(doc.get_pos)خروجی:
LEMMA view: (hello Hello) (, ,) (how how) (be are) (you you) (. .) (i I) (be am) (do doing) (fine fine)
POS view: (UH Hello) (, ,) (WRB how) (VBP are) (PRP you) (. .) (PRP I) (VBP am) (VBG doing) (JJ fine)منابع برتر
- COGCOMPNLP: Your Swiss Army Knife for NLP.; In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC-2018). 2018.
- Choosing an NLP library for analyzing software documentation: a systematic literature review and a series of experiments.; In Proceedings of the 14th International Conference on Mining Software Repositories, pp. 187-197. IEEE Press, 2017.
- https://dzone.com/articles/nlp-tutorial-using-python-nltk-simple-examples
- https://www.analyticsvidhya.com/blog/2017/04/natural-language-processing-made-easy-using-spacy-%E2%80%8Bin-python/
- https://medium.com/@datamonsters/text-preprocessing-in-python-steps-tools-and-examples-bf025f872908
- https://kleiber.me/blog/2018/02/25/top-10-python-nlp-libraries-2018/
- https://towardsdatascience.com/5-heroic-tools-for-natural-language-processing-7f3c1f8fc9f0
- https://towardsdatascience.com/nlp-engine-part-2-best-text-processing-tools-or-libraries-for-natural-language-processing-c7fd80f456e3
استفاده از این مقاله با ذکر منبع “سامانه متن کاوی فارسییار – text-mining.ir“، بلامانع است.



