در مقاله قبل به مقایسه ویژگیهای کتابخانهها و ابزارهای پردازش زبان طبیعی اشاره شد. سپس سه کتابخانه NLTK, SpaCy و CoreNLP معرفی و نمونه کد آن قرار داده شد. دیگر بخشهای این مقاله:
- بخش اول – معرفی بهترین کتابخانههای پردازش متن (NLTK, SpaCy, CoreNLP)
- بخش دوم – معرفی بهترین کتابخانههای پردازش متن (TextBlob, Pattern, StanfordNLP)
- بخش سوم – معرفی بهترین کتابخانههای پردازش متن (Polyglot, Gensim, Illinois NLP Curator)
- بخش چهارم – معرفی بهترین کتابخانههای پردازش متن (Spark-NLP, OpenNLP, SyntaxNet)
- بخش پنجم – معرفی بهترین کتابخانههای پردازش متن (GATE, RapidMiner, MALLET, FreeLing)
در جدول زیر بطور خلاصه لیست کتابخانهها و جعبه ابزارهای معروف و رایگان پردازش متن، ویژگیهای مهم آنها و ابزارهای پیادهسازی شده در هریک را گردآوری کردیم.
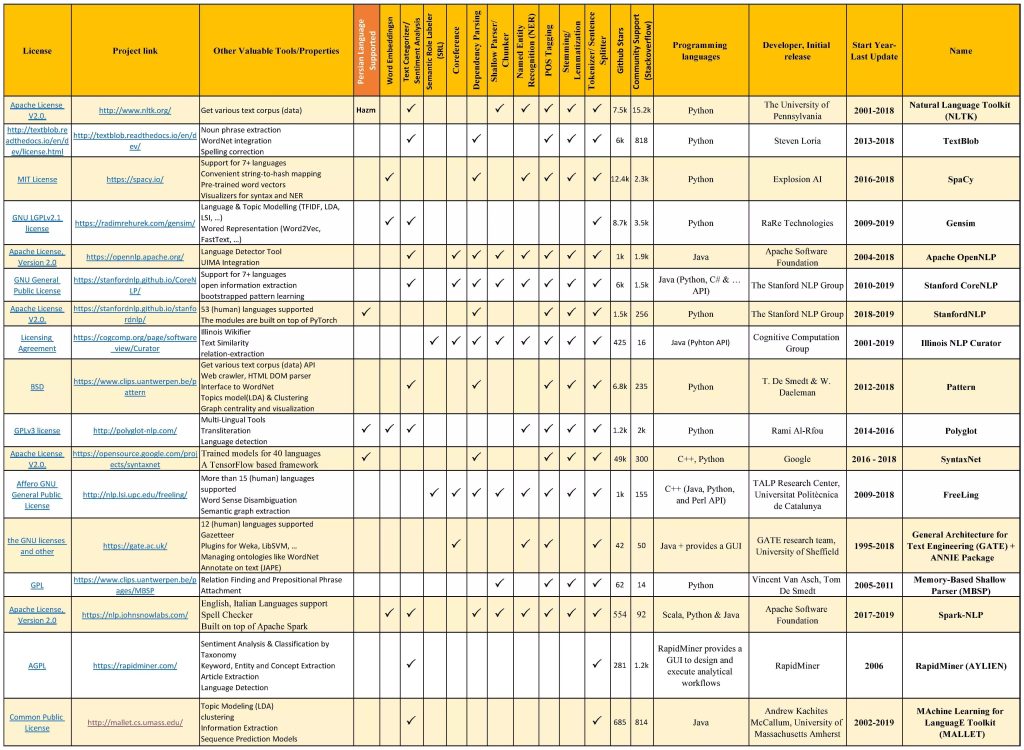
مقایسه ویژگیها و امکانات کتابخانههای (جعبه ابزار) محبوب و رایگان پردازش زبان طبیعی تا سال 2019
ذکر چند نکته درباره این جدول را لازم میدانیم. ستون دوم سال تولید و سالی که آخرین نسخه ابزار (بروزرسانی) در آن ارائه شده است را نشان میدهد. در ستون ششم، تعداد ستارهی داده شده به پروژه مربوط به هر کتابخانه در گیتهاب (یا پرستارهترین پروژه مرتبط با آنها) را به عنوان سنجه میزان محبوبیت درنظر گرفتیم. همچنین از شاخص تعداد سوالات پرسیده شده در StackoverFlow (درباره هر کتابخانه)، به عنوان مبنای میزان استفاده و جامعه بهرهبردار آن کتابخانه استفاده شده است. ستون هفدهم به پشتیبانی از زبان فارسی هر کتابخانه (همه یا بعضی از ابزارهای آن) اختصاص داده شده است. این اطلاعات و ارقام در تاریخ 15 اسفند 97 جمعآوری شدند.
در این بخش به معرفی چند جعبه ابزار پردازش متن محبوب و کاربردی دیگر میپردازیم.

کتابخانه TextBlob، یکی از ابزارهای بسیار کامل و راحت برای پردازش دادههای متنی در زبان پایتون است. این کتابخانه شامل ابزارهای مختلف پردازش زبان طبیعی از قبیل: استخراج عبارات اسمی، بنواژهیابی، برچسبزنی نقش ادت سخن، پارسر (تجزیهگر) جملات، تحلیل احساسات، دستهبندی (نایوبیز و درخت تصمیم)، ترجمه (بوسیله مترجم گوگل)، تصحیح اشتباهات املایی، اتصال به وردنت است.
نصب و راهاندازی:
pip install -U textblob
python -m textblob.download_corporaنمونه کد استفاده از امکانات مختلف این کتابخانه:
from textblob import TextBlob
text = '''TextBlob is a Python (2 and 3) library for processing textual data. It provides a consistent API for diving into common natural language processing (NLP) tasks such as part-of-speech tagging, noun phrase extraction, sentiment analysis, and more.'''
blob = TextBlob(text)
print(blob.tags)
print(blob.noun_phrases)
for sentence in blob.sentences:
print(sentence.sentiment.polarity)
blob.translate(to="fa") خروجی:
[('TextBlob', 'NNP'), ('is', 'VBZ'), ('a', 'DT'), ('Python', 'NNP'), ('2', 'CD'), ('and', 'CC'), ('3', 'CD'), ('library', 'NN'), ('for', 'IN'), ('processing', 'VBG'), ('textual', 'JJ'), ('data', 'NNS'), ('It', 'PRP'), ('provides', 'VBZ'), ('a', 'DT'), ('consistent', 'JJ'), ('API', 'NNP'), ('for', 'IN'), ('diving', 'VBG'), ('into', 'IN'), ('common', 'JJ'), ('natural', 'JJ'), ('language', 'NN'), ('processing', 'NN'), ('NLP', 'NNP'), ('tasks', 'NNS'), ('such', 'JJ'), ('as', 'IN'), ('part-of-speech', 'JJ'), ('tagging', 'NN'), ('noun', 'JJ'), ('phrase', 'NN'), ('extraction', 'NN'), ('sentiment', 'NN'), ('analysis', 'NN'), ('and', 'CC'), ('more', 'JJR')]['textblob', 'python', 'processing textual data', 'api', 'common natural language processing', 'nlp', 'noun phrase extraction', 'sentiment analysis']0.0
0.11000000000000001TextBlob یک کتابخانه پایتون (2 و 3) برای پردازش داده های متنی است. این یک API سازگار برای غواصی را به وظایف پردازش زبان مشترک طبیعی (NLP) مانند تگ های بخشی از گفتار، عبارات استخراج کلمات، تحلیل احساسات و موارد دیگر فراهم می کند.
کتابخانه Pattern
کتابخانه Pattern، یک مجموعه ماژول مناسب برای وب کاوی (Web Mining) با زبان پایتون ارائه داده است. این کتابخانه شامل API برای دریافت اطلاعات و استفاده از موتور جستجوی گوگل و مایکروسافت بینگ، مترجم گوگل، تویئتر، فیسبوک و ویکیپدیا است. همچنین مجهز به یک خزشگر وب (کرولر و پارسر قالب HTML) برای جمعآوری داده از سایر سایتهاست. ماژول پردازش زبان طبیعی این کتابخانه عملیات اصلی پردازش متن از قبیل: POS Tagger، n-gram search، تحلیل حس و اتصال به وردنت را داراست. ماژول سوم آن بخش یادگیری ماشین است که مدل بردار کلمات، خوشهبندی و دستهبندی SVM را شامل میشود. علاوه بر اینها، این کتابخانه ماژولی برای تحلیل گراف (شبکه) و مجسمسازی (visualization) نیز دارد.
توجه داشته باشید که برای کار با API تویئتر و … در ایران، باید از فیلترشکن استفاده کنید 🙂
نصب و راهاندازی:
pip install patternنمونه کد برای دریافت پیکره (مجموعه داده متنی) و استفاده از APIهای گوگل، تویئتر و کرولر:
from pattern.web import URL, DOM, plaintext, Twitter, Google
url = URL("https://text-mining.ir")
dom = DOM(url.download(cached=True, unicode=True))
print(plaintext(dom.head.by_tag("title")[0]))
twitter = Twitter(language='en')
for tweet in twitter.search('#win OR #fail', start=1, count=3):
print(tweet.text)
g = Google(license=None) # Enter your license key.
q = "Persian language needs your online help." # en
print(plaintext(g.translate(q, input="en", output="fa"))) # ar, de, es, fr, sv, ja, ... خروجی:
سامانه متن کاوی : ارائه دهنده سرویسهای متنکاوی و پردازش متن فارسی همراه با API رایگانRT @Cruise_118: RT & Follow this post before the weekend for a chance to #win these @MyRoyalUK goodies! UK only. #WinItWednesday #Competition https://t.co/5dSyXVveqz
RT @dkbooks: RT & follow by 5PM for your chance to #win 1 of 3 copies of @The_RHS Propagating Plants, publishing tomorrow! It's packed with hundreds of step-by-step tutorials and ideal for thrifty #gardening this Spring ? #WinItWednesday #competition #giveaway https://t.co/lP74RJzXap
RT @lipsticktv: #Competition Just FOLLOW US & RETWEET? https://t.co/QDwFJPFOBD to enter! #win this fab(sold out!) #DollBeauty Eye palette/pigments ?All our #giveaways are International! Ends 10th March ???? https://t.co/GU7eskh5V1زبان فارسی نیاز به کمک آنلاین شما دارد.نمونه کد ابزارهای پایه پردازش زبان طبیعی:
from pattern.en import parse, pprint, tag
s = "I eat pizza with a fork."
s = parse(s,
tokenize = True, # Tokenize the input, i.e. split punctuation from words.
tags = True, # Find part-of-speech tags.
chunks = True, # Find chunk tags, e.g. "the black cat" = NP = noun phrase.
relations = True, # Find relations between chunks.
lemmata = True, # Find word lemmata.
light = False)
# The output is a string with each sentence on a new line.
# Words in a sentence have been annotated with tags,
# for example: fork/NN/I-NP/I-PNP (NN = noun, NP = part of a noun phrase, PNP = part of a prepositional phrase.)
print(s)
# Prettier output can be obtained with the pprint() command:
pprint(s)خروجی شبه کد فوق:
I/PRP/B-NP/O/NP-SBJ-1/i eat/VBP/B-VP/O/VP-1/eat pizza/NN/B-NP/O/NP-OBJ-1/pizza with/IN/B-PP/B-PNP/O/with a/DT/B-NP/I-PNP/O/a fork/NN/I-NP/I-PNP/O/fork ././O/O/O/.
...
WORD TAG CHUNK ROLE ID PNP LEMMA
I PRP NP SBJ 1 - i
eat VBP VP - 1 - eat
pizza NN NP OBJ 1 - pizza
with IN PP - - PNP with
a DT NP - - PNP a
fork NN NP ^ - - PNP fork
. . - - - - .نمونه کد تحلیل حس:
from pattern.en import sentiment, polarity, subjectivity, positive
# The polarity() function measures positive vs. negative, as a number between -1.0 and +1.0.
# The subjectivity() function measures objective vs. subjective, as a number between 0.0 and 1.0.
# The sentiment() function returns an averaged (polarity, subjectivity)-tuple for a given string.
for word in ("amazing", "horrible", "public"):
print(word, sentiment(word))
print(sentiment("The movie attempts to be surreal by incorporating time travel and various time paradoxes,"
"but it's presented in such a ridiculous way it's seriously boring."))خروجی به شکل (نوع حس [-1,+1]، میزان حس بکاررفته[0-1]) :
amazing (0.6000000000000001, 0.9)
horrible (-1.0, 1.0)
public (0.0, 0.06666666666666667)
...
(-0.21666666666666665, 0.8)
کتابخانه StanfordNLP
کتابخانه StanfordNLP، یکی از جدیدترین کتابخانههای پردازش متن چندزبانه است که در سال 2018 ایجاد گردید. نکته قابل توجه و مهم این کتابخانه پشتیبانی بیش از 53 زبان با استفاده از آموزش مدلهای یادگیری عمیق بوسیله Pytorch و با پیکرههای آماده شده به فرمت استاندارد CoNLL است. خوشبخانه مدلهای یادگیری عمیق ابزارهای مختلف این کتابخانه، براساس پیکره خانم دکتر سراجی، برای زبان فارسی نیز آموزش داده شده و در زبان فارسی نیز قابل استفاده هستند. تصمیم جالب دانشگاه استنفورد این بود که برخلاف کتابخانه Stanford CoreNLP که با زبان جاوا نوشته شده بود، این کتابخانه کلاً با زبان محبوب پایتون نوشته شده است.
نصب و راهاندازی:
pip install stanfordnlpنمونه کد و خروجی ابزارهای مختلف این کتابخانه برای زبان فارسی:
# -*- coding: utf-8 -*-
import stanfordnlp
MODELS_DIR = r'E:\Data'
# stanfordnlp.download('fa', MODELS_DIR, False) # This downloads the Persian models for the neural pipeline (used only for the first time)
nlp = stanfordnlp.Pipeline(lang="fa", models_dir=MODELS_DIR, treebank='fa_seraji', use_gpu=False) # This sets up a default neural pipeline in Persian
doc = nlp(u"احمد و بردارش با هم به مدرسه شهید اسماعیلزاده در جنوب تهران می رفتند.")
print(*[f'text: {word.text+" "}\tlemma: {word.lemma}\tupos: {word.upos}\txpos: {word.xpos}' for sent in doc.sentences for word in sent.words], sep='\n')
print("----------------------------------------------")
doc.sentences[0].print_dependencies()خروجی نمونه کد فوق:
text: احمد lemma: احمد upos: NOUN xpos: N_SING
text: و lemma: و upos: CCONJ xpos: CON
text: بردار lemma: بردار upos: NOUN xpos: N_SING
text: ش lemma: او upos: PRON xpos: PRO
text: با lemma: با upos: ADP xpos: P
text: هم lemma: هم upos: PRON xpos: PRO
text: به lemma: به upos: ADP xpos: P
text: مدرسه lemma: مدرسه upos: NOUN xpos: N_SING
text: شهید lemma: شهید upos: NOUN xpos: N_SING
text: اسماعیلزاده lemma: اسماعیلزاده upos: ADJ xpos: ADJ
text: در lemma: در upos: ADP xpos: P
text: جنوب lemma: جنوب upos: NOUN xpos: N_SING
text: تهران lemma: تهران upos: NOUN xpos: N_SING
text: می lemma: می upos: NOUN xpos: N_SING
text: رفتند lemma: رفت#رو upos: VERB xpos: V_PA
text: . lemma: . upos: PUNCT xpos: DELM
----------------------------------------------
('احمد', '15', 'nsubj')
('و', '3', 'cc')
('بردار', '1', 'conj')
('ش', '3', 'nmod:poss')
('با', '6', 'case')
('هم', '15', 'obl')
('به', '8', 'case')
('مدرسه', '15', 'obl')
('شهید', '8', 'nmod:poss')
('اسماعیل\u200cزاده', '9', 'amod')
('در', '12', 'case')
('جنوب', '9', 'nmod')
('تهران', '12', 'nmod:poss')
('می', '15', 'compound:lvc')
('رفتند', '0', 'root')
('.', '15', 'punct')منابع برتر
- Universal Dependency Parsing from Scratch In Proceedings of the CoNLL 2018 Shared Task: Multilingual Parsing from Raw Text to Universal Dependencies, pp. 160-170, 2018.
- https://www.analyticsvidhya.com/blog/2018/02/natural-language-processing-for-beginners-using-textblob/
- https://medium.com/@datamonsters/text-preprocessing-in-python-steps-tools-and-examples-bf025f872908
- https://kleiber.me/blog/2018/02/25/top-10-python-nlp-libraries-2018/
- https://towardsdatascience.com/5-heroic-tools-for-natural-language-processing-7f3c1f8fc9f0
- https://towardsdatascience.com/nlp-engine-part-2-best-text-processing-tools-or-libraries-for-natural-language-processing-c7fd80f456e3
استفاده از این مقاله با ذکر منبع “سامانه متن کاوی فارسییار – text-mining.ir“، بلامانع است.