
امروزه با توسعه ابزارهای ارتباطی، پردازش زبان طبیعی (Natural language processing – NLP) محبوبیت و جایگاه ویژهای یافته است. بخصوص با ورود یادگیری عمیق به پردازش و فهم زبان، تحولی در این حوزه رخ داده است. یکی از فیلدهای مهم پردازش زبانهای طبیعی، پردازش متن است. خوشبختانه امروزه برای پردازش متن ابزارهای (کتابخانههای) بسیار مفید و منبع باز، بخصوص در زبان پایتون، ایجاد شده است. خبر خوب دیگر اینکه در سالهای اخیر توجه توسعه دهندگان این ابزارها به سمت چندزبانه شدن بوده است.
در جدول زیر بطور خلاصه لیست کتابخانهها و جعبه ابزارهای معروف و رایگان پردازش متن، ویژگیهای مهم آنها و ابزارهای پیادهسازی شده در هریک را گردآوری کردیم.
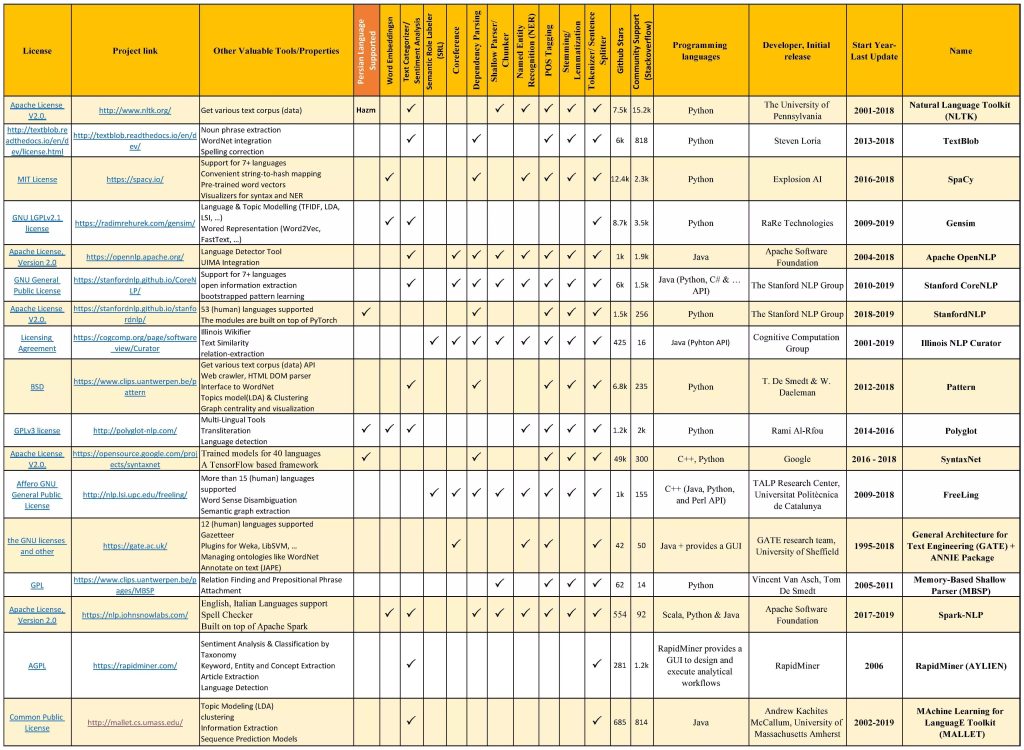
مقایسه ویژگیها و امکانات کتابخانههای (جعبه ابزار) محبوب و رایگان پردازش زبان طبیعی تا سال 2019
ذکر چند نکته درباره این جدول را لازم میدانیم. ستون دوم سال تولید و سالی که آخرین نسخه ابزار (بروزرسانی) در آن ارائه شده است را نشان میدهد. در ستون ششم، تعداد ستارهی داده شده به پروژه مربوط به هر کتابخانه در گیتهاب (یا پرستارهترین پروژه مرتبط با آنها) را به عنوان سنجه میزان محبوبیت درنظر گرفتیم. همچنین از شاخص تعداد سوالات پرسیده شده در StackoverFlow (درباره هر کتابخانه)، به عنوان مبنای میزان استفاده و جامعه بهرهبردار آن کتابخانه استفاده شده است. ستون هفدهم به پشتیبانی از زبان فارسی هر کتابخانه (همه یا بعضی از ابزارهای آن) اختصاص داده شده است. این اطلاعات و ارقام در تاریخ 15 اسفند 97 جمعآوری شدند.
حال قصد معرفی مختصر و نمونه کد بعضی از کتابخانههای محبوب فوق را داریم. سعی شده است در توضیحات ذیل از تکرار مشخصات و لیست ابزارهای پیادهسازی شده (که در جدول فوق مشخص شده) برای هر کتابخانه جلوگیری شود.
دیگر بخشهای این مقاله:
- بخش اول – معرفی بهترین کتابخانههای پردازش متن (NLTK, SpaCy, CoreNLP)
- بخش دوم – معرفی بهترین کتابخانههای پردازش متن (TextBlob, Pattern, StanfordNLP)
- بخش سوم – معرفی بهترین کتابخانههای پردازش متن (Polyglot, Gensim, Illinois NLP Curator)
- بخش چهارم – معرفی بهترین کتابخانههای پردازش متن (Spark-NLP, OpenNLP, SyntaxNet)
- بخش پنجم – معرفی بهترین کتابخانههای پردازش متن (GATE, RapidMiner, MALLET, FreeLing)

کتابخانه Natural Language Toolkit – NLTK
کتابخانه NLTK یکی از جامعترین و قدیمیترین کتابخانههای پردازش زبان طبیعی در پایتون است. این کتابخانه پایه و استانداردی برای کتابخانههای پردازش متن محسوب شده و برای کاربردهای پژوهشی فوقالعاده است. یکی از ویژگیهای خوب این کتابخانه امکان اتصال به پیکرههای مختلف متنی است.
نصب و راهاندازی:
# pip install nltk
import nltk
nltk.download('punkt') # tokenizer
nltk.download('stopwords') # remove stop-words
nltk.download('averaged_perceptron_tagger') # pos tagger
nltk.download('maxent_ne_chunker') # chunker
nltk.download('words') # ner
nltk.download('treebank') # dependency parser
nltk.download('wordnet') # lematizerمثالهایی برای تقطیع جمله، کلمات و حذف کلمات زائد با این ابزار:
from nltk.tokenize import word_tokenize, sent_tokenize
from nltk.corpus import stopwords
stopWords = set(stopwords.words('english'))
sentence = "At eight o'clock on Thursday morning. Arthur didn't feel very good."
print(sent_tokenize(sentence))
words = word_tokenize(sentence)
print(words)
wordsFiltered = []
for w in words:
if w not in stopWords:
wordsFiltered.append(w)
print(wordsFiltered)خروجی نمونه کد بالا:
["At eight o'clock on Thursday morning.", "Arthur didn't feel very good."]
['At', 'eight', "o'clock", 'on', 'Thursday', 'morning', '.', 'Arthur', 'did', "n't", 'feel', 'very', 'good', '.']
['At', 'eight', "o'clock", 'Thursday', 'morning', '.', 'Arthur', "n't", 'feel', 'good', '.']نمونه کد برای ریشهیابی و بنواژهیابی (در ادامه کد فوق):
from nltk.stem import PorterStemmer
from nltk.stem import WordNetLemmatizer
pstemer = PorterStemmer()
wordnet_lemmatizer = WordNetLemmatizer()
words = word_tokenize("gaming, the gamers play games")
for word in words:
print(word + ":" + pstemer.stem(word))
for word in words:
print(word + ":" + wordnet_lemmatizer.lemmatize(word))خروجی:
gaming:game
,:,
the:the
gamers:gamer
play:play
games:game
...
gaming:gaming
,:,
the:the
gamers:gamers
play:play
games:gameنمونه کد برای برچسبزنی نقش ادت سخن، قطعهبند و شناسایی موجودیتها و نهایتاً پارسر وابستگی (در ادامه کد فوق):
words = word_tokenize("Mark and John are working at Google.")
tagged = nltk.pos_tag(words)
print(tagged)
entities = nltk.chunk.ne_chunk(tagged)
print(entities)
from nltk.corpus import treebank
t = treebank.parsed_sents('wsj_0001.mrg')[0]
print(t) # t.draw()خروجی:
[('Mark', 'NNP'), ('and', 'CC'), ('John', 'NNP'), ('are', 'VBP'), ('working', 'VBG'), ('at', 'IN'), ('Google', 'NNP'), ('.', '.')]
...
(S
(PERSON Mark/NNP)
and/CC
(PERSON John/NNP)
are/VBP
working/VBG
at/IN
(ORGANIZATION Google/NNP)
./.)
...
(S
(NP-SBJ
(NP (NNP Pierre) (NNP Vinken))
(, ,)
(ADJP (NP (CD 61) (NNS years)) (JJ old))
(, ,))
(VP
(MD will)
(VP
(VB join)
(NP (DT the) (NN board))
(PP-CLR (IN as) (NP (DT a) (JJ nonexecutive) (NN director)))
(NP-TMP (NNP Nov.) (CD 29))))
(. .))
کتابخانه SpaCy
کتابخانه SpaCy با زبان پایتون برای متن کاوی تهیه شده و با اجرا روی Cython به سرعت مشهور است. این کتابخانه ارتباط خوبی با ابزارهای یادگیری ماشین و یادگیری عمیق از قبیل gensim ،Keras ،TensorFlow و scikit-learn داشته و برای پیشپردازش متن در این حوزه بسیار کاربردی است. به گفته توسعهدهندگان این کتابخانه ماموریت این ابزار، فراهمسازی بهترین ابزار در دسترس برای عملیات کاربردی پردازش زبان طبیعی است. این کتابخانه چندزبانه است ولی متاسفانه در حال حاضر از زبان فارسی پشتیبانی نمیکند. اگرچه امکان افزودن مدلهای زبانهای دیگر را دارد.
نصب و راهاندازی:
pip install spacy
python -m spacy download en_core_web_smمثالهایی برای استفاده از این ابزار:
import spacy
# Load English tokenizer, tagger, parser, NER and word vectors
nlp = spacy.load('en_core_web_sm')
# Preprocessing (Process whole documents)
text = u'Apple is looking at buying U.K. startup for $1 billion.'
doc = nlp(text)
# Tokenization, Stopwords, Lemmatization, POS tagging, Dependency Parsing
for token in doc:
print(token.text, token.is_stop, token.lemma_, token.pos_, token.tag_, token.dep_)
# Find named entities, phrases and concepts
for entity in doc.ents:
print(entity.text, entity.label_, ent.start_char, ent.end_char)
# Determine semantic similarities
doc1 = nlp(u"my fries were super gross")
doc2 = nlp(u"such disgusting fries")
similarity = doc1.similarity(doc2)
print(doc1.text, doc2.text, similarity)خروجی:
(u'Apple', False, u'apple', u'PROPN', u'NNP', u'nsubj')
(u'is', True, u'be', u'VERB', u'VBZ', u'aux')
(u'looking', False, u'look', u'VERB', u'VBG', u'ROOT')
(u'at', True, u'at', u'ADP', u'IN', u'prep')
(u'buing', False, u'bu', u'VERB', u'VBG', u'pcomp')
(u'U.k', False, u'u.k', u'PROPN', u'NNP', u'dep')
(u'.', False, u'.', u'PUNCT', u'.', u'punct')
(u'startup', False, u'startup', u'VERB', u'VBG', u'ROOT')
(u'for', True, u'for', u'ADP', u'IN', u'prep')
(u'$', False, u'$', u'SYM', u'$', u'quantmod')
…
(u'Apple', u'ORG', 0, 5)
(u'$1 billion', u'MONEY', 43, 53)
…
my fries were super gross such disgusting fries 0.7139701576579747
کتابخانه Stanford’s CoreNLP
کتابخانه Stanford’s CoreNLP، ابزار بسیار مناسب برای تحلیلهای دستوری برای زبان است. این ابزار با زبان جاوا نوشته شده ولی API آن برای زبانهای مختلف از قبیل پایتون و سیشارپ موجود است. چندزبانه بودن و تمرکز بر استخراج اطلاعات باز از متن از ویژگیهای اصلی این ابزار است.
مثالهایی برای استفاده از این ابزار:
import edu.stanford.nlp.coref.data.CorefChain;
import edu.stanford.nlp.ling.*;
import edu.stanford.nlp.ie.util.*;
import edu.stanford.nlp.pipeline.*;
import edu.stanford.nlp.semgraph.*;
import edu.stanford.nlp.trees.*;
import java.util.*;
public class BasicPipelineExample {
public static String text = "Joe Smith was born in California. " +
"In 2017, he went to Paris, France in the summer. " +
"His flight left at 3:00pm on July 10th, 2017. ";
public static void main(String[] args) {
// set up pipeline properties
Properties props = new Properties();
// set the list of annotators to run
props.setProperty("annotators", "tokenize,ssplit,pos,lemma,ner,parse,depparse,coref,kbp,quote");
// set a property for an annotator, in this case the coref annotator is being set to use the neural algorithm
props.setProperty("coref.algorithm", "neural");
// build pipeline
StanfordCoreNLP pipeline = new StanfordCoreNLP(props);
// create a document object
CoreDocument document = new CoreDocument(text);
// annnotate the document
pipeline.annotate(document);
// examples
// 10th token of the document
CoreLabel token = document.tokens().get(10);
System.out.println(token);
// list of the part-of-speech tags for the second sentence
List<String> posTags = sentence.posTags();
System.out.println(posTags);
}
}برای دریافت مثالهای بیشتر و کامل به مستندات یا صفحه آموزش این کتابخانه مراجعه بفرمایید. همچنین برای استفاده از این کتابخانه در زبان پایتون، کتابخانههای غیررسمی زیادی وجود دارد که میتوانید از آنها استفاده کنید ولی پیشنهاد میشود که از پروژه رسمی آن به نام Stanford CoreNLP Python Interface استفاده کنید. برای آشنایی با نحوه استفاده از کتابخانه Stanford CoreNLP در سایر زبانها از قبیل C#، Go، PHP، Perl، Ruby، Scala، … به این صفحه مراجعه بفرمایید.
نتیجهگیری
در این مقاله، کتابخانهها و جعبه ابزارهای محبوب پردازش زبان طبیعی در زبانهای مختلف برنامهنویسی معرفی شدند. از جمله آنها میتوان به NLTK، spaCy، TextBlob، Gensim، Pattern، Polyglot، Stanford CoreNLP، SyntaxNet، FreeLing و GATE اشاره کرد. البته هنوز کتابخانههای دیگری برای پردازش متن (بخصوص در زبان پایتون) مانند: Vocabulary، PyNLPl، MontyLingua NlpNet و … وجود دارند که در این مقاله به معرفی آنها پرداخته نشده است. انشالله در مقالاتی جداگانه به معرفی سایر کتابخانههای محبوب پردازش متن خواهیم پرداخت.
همانطور که مستحضر هستید، در سالهای اخیر تمایل دانشمندان داده به سمت زبان پایتون بسیار زیاد بوده است. حوزهی پردازش زبان طبیعی نیز از این امر مستثنی نبوده و اغلب کتابخانهها و ابزارهای جدید با زبان پایتون توسعه داده شده یا پوششی (wrapper) از زبان پایتون برای آنها تهیه شده است.
در پایان، پنج کتابخانهی پردازش متن که بیشترین طرفدار را دارند با هم از نظر محبوبیت در 5 سال اخیر مقایسه نمودیم.
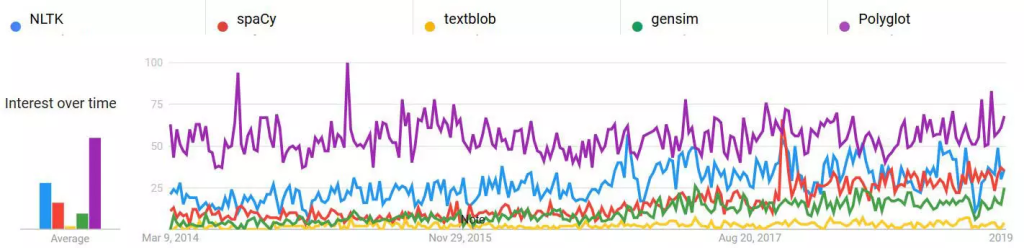
مقایسه محبویت پرطرفدارترین کتابخانههای پردازش متن (استخراج شده از Google Trends)
در این مقاله مقایسه جالبی بین سرعت اجرای چهار کتابخانه SpaCy ،NLTK ،Stanford CoreNLP وIllinois COGCOMP NLP روی سختافزاری با مشخصات CPU=12×Intel Xeon six-core 3.2GHz و Memory=32GB انجام شده است:
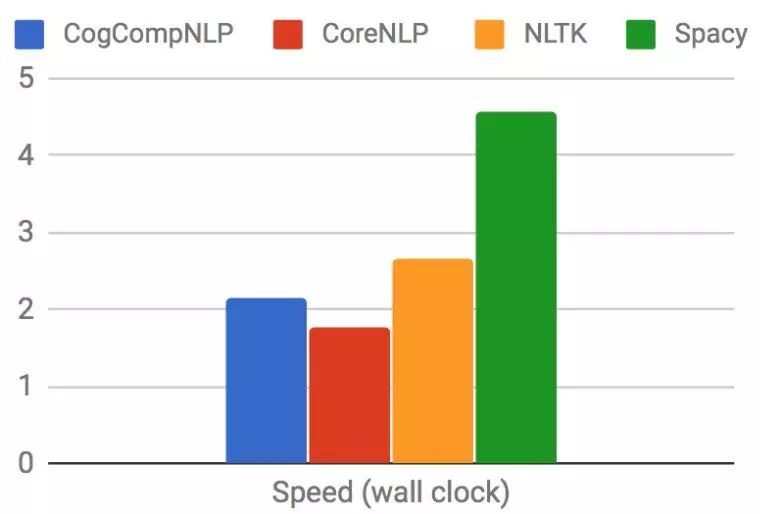
مقایسه سرعت اجرای چهار کتابخانه پردازش زبان طبیعی برای تقطیع جملات و کلمات، برچسبزنی نقش ادات سخن و موجودیتهای نامی (مقدار بیشتر بهتر هست)
همچنین مطابق در آزمایشات انجام شده در همین مقاله، سرعت (کارایی) ابزارهای NLTK و TextBlob در یک سطح هستند.
در مقاله دیگری، روی دقت چهار کتابخانه Stanford CoreNLP، Google SyntaxNet، SpaCy و NLTK بر روی سه پیکره مختلف، مطالعه شده و نهایتاً مشخص شد که کتابخانه NLTK و SpaCy از دقت خوبی برخوردار هستند:
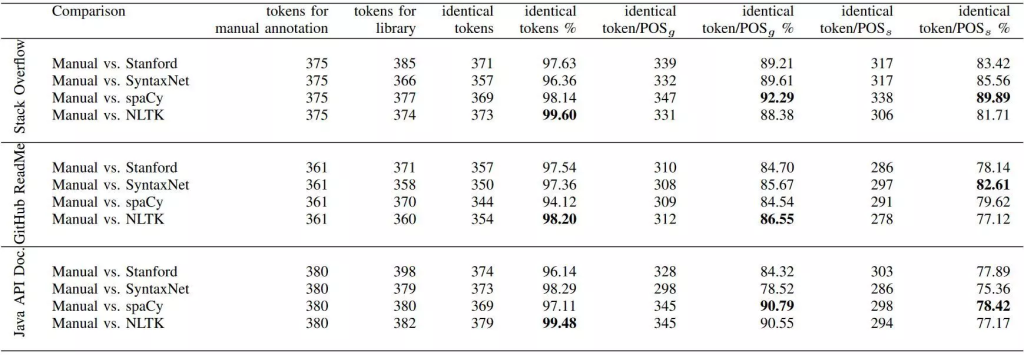
مقایسه دقت (accuracy) چهار کتابخانه پردازش زبان طبیعی در شناسایی کلمات (توکن) و برچسبزنی نقش ادات سخن (مقدار بیشتر بهتر هست)
منابع برتر
- COGCOMPNLP: Your Swiss Army Knife for NLP.; In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC-2018). 2018.
- Choosing an NLP library for analyzing software documentation: a systematic literature review and a series of experiments.; In Proceedings of the 14th International Conference on Mining Software Repositories, pp. 187-197. IEEE Press, 2017.
- https://dzone.com/articles/nlp-tutorial-using-python-nltk-simple-examples
- https://www.analyticsvidhya.com/blog/2017/04/natural-language-processing-made-easy-using-spacy-%E2%80%8Bin-python/
- https://medium.com/@datamonsters/text-preprocessing-in-python-steps-tools-and-examples-bf025f872908
- https://kleiber.me/blog/2018/02/25/top-10-python-nlp-libraries-2018/
- https://towardsdatascience.com/5-heroic-tools-for-natural-language-processing-7f3c1f8fc9f0
- https://towardsdatascience.com/nlp-engine-part-2-best-text-processing-tools-or-libraries-for-natural-language-processing-c7fd80f456e3
استفاده از این مقاله با ذکر منبع “سامانه متن کاوی فارسییار – text-mining.ir“، بلامانع است.




