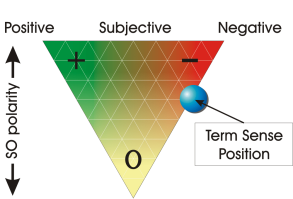
وقتی صحبت از نظر کاوی پیش میآید ابتدا ذهن همه به دنبال دستهبندی حسی (تحلیل احساسات) میرود. ولی دستهبندی حسی یا تشخیص حس نویسنده از متن یکی از فیلدهای پرطرفدار و کاربردی نظرکاوی است درحالیکه در این حوزه زمینههای تحقیقاتی مفید دیگری نیز وجود دارد.
در مقاله قبل درباره تعاریف و مقدمات نظرکاوی صحبت کردیم. حالا قصد معرفی زمینههای مختلف تحقیقاتی در حوزه نظر کاوی را داریم. در شکل زیر زمینههای کلی نظر کاوی نشان داده شده است.
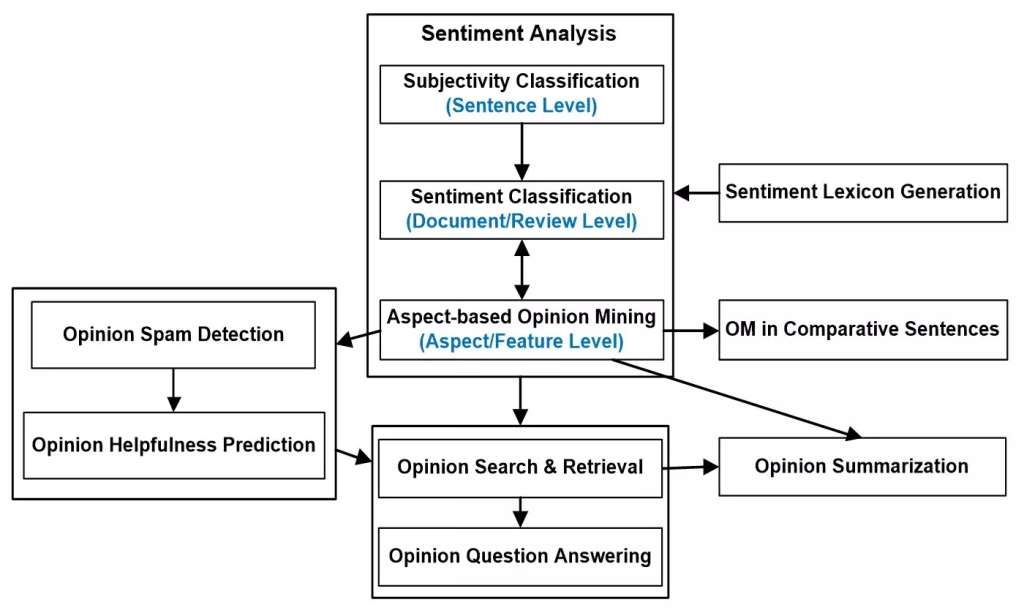
دستهبندی زمینههای تحقیقاتی مرتبط با نظر کاوی به همراه نمایش ارتباط بین آنها
تولید مجموعه لغات حسی
ساخت مجموعه لغات حاوی حس (بار حسی مثبت و منفی)، یکی از روشهای مورد توجه محققان برای تشخیص حس جملات است. بطور کلی روشهای تحلیل احساسات (دستهبندی حسی نظرات) را میتوان به سه گروه تقسیمبندی نمود :
- روشهای مبتنی بر واژهنامه حسی و استفاده از دانش زمینه (یادگیری بدون ناظر یا شبهناظر)
- روشهای یادگیری باناظر
- روشهای تشخیص حس عبارات با استفاده از محاسبه شباهت و روابط معنایی کلمات
دقت روشهای مبتنی بر واژهنامه حسی کاملاً وابسته به مجموعه لغات حاوی حس و وزنهای از پیش تعیین شده است. این روشها بدون نیاز به پیکره برچسبخورده و برای حوزههای عمومی قابل استفاده هستند. در رویکرد دوم (برای دستهبندی حسی متون) نیز میتوان از واژگان حسی به عنوان یکی از ویژگیهای مهم متن نظرات استفاده نمود.
بطور کلی از سه رویکرد ذیل برای تولید واژهنامههای حسی استفاده میشوند:
- مبتنی بر پیکره
- مبتنی بر لغتنامه و پایگاه دانش
- مبتنی بر روشهای یادگیر باناظر
روشهای مبتنی بر پیکره از پیکرههای متنی نسبتاً بزرگ و از قوانین زبانشناسی استفاده میکنند. معمولاً از ابن رویکرد برای ایجاد واژهنامه حسی برای یک دامنه (موضوع) خاص استفاده میشود. البته با درنظر گرفتن پیکرههای متنی بزرگ میتوان از این رویکرد برای تولید واژهنامههای حسی عمومی (مستقل از دامنه) نیز استفاده کرد.
روشهای مبتنی بر لغتنامه اغلب از شبکه واژگان (WordNet) برای تعیین روابط معنایی و محاسبه بار حسی کلمات استفاده میکنند. یکی از معروفترین منابع ایجاد شده مبتنی بر اساس این رویکرد، شبکه واژگان حسی انگلیسی به نام سنتی وردنت (SentiWordNet) است. شبکه واژگان حسی انگلیسی یکی از بهترین منابع موجود برای شناسایی کلمات حسی است که بر اساس تعیین میزان بار حسی هر گروه کلمات هممعنی در شبکه واژگان انگلیسی دانشگاه پرینستون (Princeton WordNet یا PWN) ایجاد شده است. شبکه واژگان حسی انگلیسی برای هر گروه کلمات، میزان بار حسی منفی، مثبت و همچنین مقدار غیرحسی بودن (با توجه به مقدار حس مثبت و منفی) را با عددی دربازه [0, +1] مشخص میکند.
در رویکرد ساخت لغتنامه حسی با استفاده از روشهای یادگیر باناظر، نیاز به دادههای آموزشی دارای برچسب حسی اولیه میباشد. بدلیل مشکلات برچسبگذاری حسی کلمات (تهیه پیکره آموزشی) اغلب از این رویکرد برای استخراج واژگان حسی در دامنه محدود (خاص) نظرات استفاده میشود. در عمل، معمولاً این رویکرد با روشهای مبتنی بر پایگاه دانش و یا پیکره نظرات (با قالب مشخص) ترکیب میشود.
تحلیل احساسات (تشخیص میزان رضایتمندی نویسنده از روی متن)
بیشتر پژوهشهای اولیه در زمینه نظرکاوی، سعی در دستهبندی حسی نظرات یا تعیین حس کلی یک متن، در قالب دو دسته حس مثبت و منفی، داشتند. در ادامه، پژوهشگران سعی در تعیین درجه (میزان) رضایتمندی یا نارضایتی (به جای دستهبندی دو حالته) در متن نمودند. در تحلیل حس متون سعی میشود تا قبل از شروع کار، نوع متن (از نظر حسی) یا بخشهای آن از نظر عینی (objective) یا ذهنی (subjective) مشخص شود. منظور از ذهنی بودن متن، متنی است که وابسته به طرز تفکر فردی بوده و دارای نظر و حس آن فرد میباشد. منظور از عینی بودن متن نیز همان حقایق یا متنی است که حاوی نظر نویسنده نمیباشد.
پس ابتدا لازم است تا تحلیل ذهنیت روی متن انجام شود زیرا ممکن است متن مورد بررسی فقط شامل حقایق باشد (مانند اخبار)، بدون اینکه حس یا نظر نویسنده را بیان کرده باشد. برای تحلیل ذهنیت از روشهای دستهبندی بدون ناظر (unsupervised)، باناظر (supervised)، شباهت جملات یا استفاده از لیست اولیه از کلمات حاوی حس و شبکه واژگان (وردنت یا WordNet) یا روش متنی بر گراف برای مرزبندی بخشهای ذهنی و عینی در یک متن استفاده شده است.
مشکل دیگر این دسته پژوهشها، فرض یکسان بودن نظر نویسنده در تمام متن هست. به عبارت دیگر یک متن میتواند دارای نظرات مختلف یا بیش از یک حس باشد. برای مثال در متن “این فیلم فروش بسیار خوبی داشت و از بازیگران مطرحی استفاده نموده است. بازیگر اول آن فوق العاده طبیعی و عالی نقش خود را ایفا نمود. داستان این فیلم نیز برای من بسیار جالب توجه بود. البته به نظر من این فیلم در رسیدن به هدف خود شکست خورد.” همانطور که مشاهده میشود، نویسنده این عبارت نظرات متفاوتی را در یک متن بیان نموده است و با وجود بیان عبارات حسی مثبت فراوان، نظر کلی او منفی بوده است.
مشکل دیگری که در پژوهشهای اولیه وجود داشت این است که فرض بر این است که همه متن یا متون جمعآوری شده به یک موضوع اشاره دارند. در حالیکه ممکن است بخشهای مختلف متن یا متون مختلف جمعآوری شده، به موضوعات متفاوتی پرداخته باشند. پس لازم هست قبل از تحلیل حس، موضوع بخشهای مختلف شناسایی و جدا از هم بررسی شوند.
در نتیجه، محققان نظرکاوی کار تحلیل حس را در سطح جمله (Sentence level sentiment analysis) یا بخشهای معنایی (Semantic frame) اشارهکننده به یک موضوع، ادامه دادند. بدین ترتیب برای هر جمله علاوه تحلیل ذهنیت، تحلیل حس نیز در سطح جمله انجام میگرفت. البته در این روش نیز فرض شده بود که هر جمله تنها حاوی یک حس است که این فرض در بعضی از نمونهها صادق نیست. علاوه بر این، در بسیاری از موارد تحلیل حس در سطح جمله، موجودیتها (موضوعات) و ویژگیهای آنها در متن، بخوبی شناسایی و تفکیک نمیشدند.
بدلیل مشکلات موجود در تحلیل حس در سطح متن (سند) و در سطح جمله، رویکرد نظرکاوی مبتنی بر ویژگی یا جنبه (Feature/Aspect based opinion mining) مطرح شد. در این رویکرد ابتدا موجودیتها (موضوعات) و ویژگیهای بیان شده برای آنها از متن استخراج و سپس به تحلیل حس بیان شده برای هر یک از این ویژگیها میپردازند. استخراج موجودیت و ویژگیهای مورد بحث (هدف نویسنده) و رتبهبندی نظر یا حس بیان شده در مورد هر ويژگی، میتواند اطلاعات بسیار کامل و مفیدی را برای تصمیمگیری فراهم آورد. برای مثال در جمله “کیفیت تماس گوشی نوکیا خوب است ولی قیمت بالایی دارد”؛ درباره موجودیت (هدف نظرسنجی) گوشی موبایل نوکیا و در مورد ویژگیهای (یا جنبههای) کیفیت تماس و قیمت به ترتیب نظرات مثبت و منفی بیان شده است.
خلاصهسازی نظرات
بر اساس تحلیل احساسات در سطح ویژگی (جنبه)، خلاصهسازی ساختیافته نظرات شکل گرفته است که اطلاعات مفید و طبقهبندی شدهای نسبت به خلاصهسازهای سنتی در اختیار کاربران قرار میدهد. قبلاً در این مقاله توضیحات مفصلی درباره انواع روشهای خلاصهسازی نظرات و تفاوتهای آنها بیان شده است.
تحلیل نظرات مقایسهای
تحلیل نظرات مقایسهای در بسیاری از کاربردهای تحلیل بازار، نظرسنجیها و بطور کلی هوش رقابتی، از جمله پیداکردن بینش بازار و عملکرد فروش یک شرکت در مقایسه با رقبای آن، مورد استفاده قرار میگیرد.
بدین منظور ابتدا لازم است که گونههای مختلف جملات مقایسهای شناسایی و سپس اجزای آن مشخص شوند. محققان گونههای ذیل را برای یک جمله در متن نظرات در نظر میگیرند:
- جمله غیرمقایسهای: هیچ گونه مقایسه در جمله صورت نگرفته است.
- جمله مقایسهای (Comparative Sentence): به نوعی نویسنده چند موجودیت را مورد مقایسه قرار داده است.
- قیاسی (Gradable): برتری یک یا چند موجودیت نسبت به دیگر موجودیتها
- قیاس نامساوی (Non-Equal Gradable): بیشتر یا کمتر کیفی یک موجودیت نسبت به دیگر موجودیتها. مثل: کیفیت دوربین iPhone X خیلی بهتر از دوربین S9 است.
- قیاس مساوی (Equality): مثل: دوربینهای S4 و iPhone X فرق چندانی ندارند.
- قیاس تفضیل (Superlative): مثل: iPhone X بهترین دوربین رو داره.
- غیرقیاسی (Non-gradable): یک موجودیت یک ویژگی دارد ولی موجودیت(های) دیگر آن ویژگی را ندارد (ندارند).
- قیاسی (Gradable): برتری یک یا چند موجودیت نسبت به دیگر موجودیتها
در مرحله بعد اجزاء ذیل (در صورت وجود) از جملات مقایسهای استخراج میشوند:
- موجودیت اول: موجودیت اصلی یا طرف اول مقایسه.
- موجودیت دوم: موجودیت(های) دیگر که مورد مقایسه با موجودیت اصلی قرار گرفتند.
- کلمه یا عبارت بیان مقایسه مثل: فرقی نداره، خیلی بهتر، بهترین، …
- ویژگیها مثل: دوربین، کیفیت ساخت، …
- نوع مقایسه: غیر قیاسی، قیاس تفضیلی، قیاس نامساوی یا قیاس مساوی
در بعضی از تحقیقات اجزاء دیگری از جملات مقایسهای مانند زمان مقایسه، فرد یا مرجع مقایسه کننده، موجودیت برتر (ترجیح داده شده) و … نیز مورد توجه قرار گرفتند.
تشخیص نظرات اسپم (هرز)
با توجه به گسترش کسبوکارهای دیجیتال در اینترنت و فضای مجازی طبیعتاً تعداد کاربران آنها افزایش چشمگیری پیدا کرده است. پس تعامل و دریافت نظرات و فیدبک کاربران تبدیل به یکی از چالشهای کسبوکارهای نسل جدید شده است. دریافت و نمایش نظرات و تجربیات مشتریان قبلی میتواند کمک بسزایی به انتخاب کاربران دیگر و جذب مشتریان جدید نماید. ولی در کنار این مزایا، انتشار خودکار همه پیامها و نظرات کاربران و مشتریان میتواند چالشها و مشکلات جدی برای کسب و کارها ایجاد نماید.
منظور از تشخیص اسپم نظرات شناسایی پیامهای تبلیغاتی، غیر اخلاقی و توهین آمیز یا نژادپرستانه، غیرانسانی (نوشته شده بوسیله ربات) و … است.
معمولاً برای حل این مساله از رویکردهای یادگیری ماشین استفاده میشود. البته چالش اصلی این رویکردها تهیه پیکره برچسب خورده مناسب با زمینه کسب و کار مورد نظر است.
تعیین میزان مفید بودن نظرات
به هرگونه محتوایی که توسط کاربر ایجاد شود، محتوای تولید شده توسط کاربر میگویند.
با توجه به اهمیت تحلیل خودکار نظرات و محتوای تولید شده توسط کاربران (user generated content یا UGC) در رسانههای اجتماعی یا هر بستر دیجیتال دیگر، انتخاب و جداسازی نظرات مناسب و مفید ضروری است. نوعاً مشاهده میشود که کاربران در بخش نظرات، سوالات یا درخواست خود را بیان میکنند. همچنین درج مطالب اضافه و غیر ضروری و نامرتبط در بخش نظرات بسیار رایج است.
یکی از راههای متداول این مساله کمک گرفتن از خود کاربران برای تعیین نظرات مناسب و مفید است. معمولاً در در بخش نظرات سایتهای مختلف بخشی برای امتیازدهی به نظرات (مفید یا غیرمفید بودن نظر) توسط سایر کاربران وجود دارد. ولی انجام این عمل، در بعضی از رسانهها مانند شبکههای اجتماعی شناسایی مطالب و نظرات غیرمفید یا جعلی بسیار پیچیده و دشوار است.
میتوان شناسایی شایعات و نظرات جعلی و غیرواقعی، که امروزه یکی از چالشهای جدی فضای مجازی و شبکههای اجتماعی است، را زیرمجموعه این دسته برشمرد.
استفاده از این مقاله با ذکر منبع (سامانه متن کاوی فارسییار)، بلامانع است.